数据库原理与应用(外教版)
数据库原理与应用(外教版)
4.22
1.主码(primary key):
主码也称为主键,是表中的一个或多个字段(列)的组合,其值能够唯一地标识表中的每一行记录,即表中的任意两条记录的主码值都不相同,并且主码不允许包含空值(NULL)。
例如,在一个 Students 表中,包含 StudentID(学生编号)、Name(姓名)、Age(年龄)等字段,StudentID 就可以设置为主码。因为每个学生的编号都是唯一的,通过 StudentID 能够准确地确定每一个学生的记录。
1 | create table Students( |
主码的作用主要有:
- 保证数据的唯一性:确保表中的每一行数据都是独一无二的,避免出现重复记录。
- 作为表的唯一标识:方便在数据库操作中(如查询、更新、删除等)准确地定位和操作特定的记录。
- 建立表之间的联系:与其他表的外码配合,建立表之间的关联关系。
2.外码(foreign key):
外码也叫外键,是一个表中的一个或多个字段(列),它的值与另一个表(称为主表或父表)的主码或候选码相对应。外码用于建立两个表之间的关联关系,通过外码可以实现数据的参照完整性。
例如,有一个 Orders 表,包含 OrderID(订单编号)、CustomerID(客户编号)、OrderDate(订单日期)等字段,同时有一个 Customers 表,包含 CustomerID(客户编号)、CustomerName(客户姓名)等字段。在 Orders 表中的 CustomerID 就可以设置为外码,它参照了 Customers 表中的 CustomerID 主码。
1 | create table Customers( |
外码的作用主要有:
- 建立表间关系:明确地表示出两个表之间的关联,使得数据库中的数据能够更好地组织和管理。
- 保证数据的一致性和完整性:当对主表中的主码进行修改或删除操作时,数据库管理系统会根据外码约束规则进行相应的处理,以确保相关表中的数据保持一致。例如,当删除
Customers表中一个客户的记录时,如果Orders表中有该客户的订单记录,根据外码约束的设置(如级联删除、拒绝删除等),可以保证数据的完整性不被破坏。
3.关系代数
(1)选择select(
选择操作是从关系中挑选出满足给定条件的元组。设 R 为一个关系,F 是一个条件表达式,那么选择操作可表示为$ \sigma_{F}(R)$。
示例:假设存在一个关系 Students,包含字段 StudentID、Name、Age。若要挑选出年龄大于 20 的学生,操作如下:
-- SQL 示例
SELECT * FROM Students WHERE Age > 20;
在关系代数里,可表示成$ \sigma_{Age > 20}(Students)$。
(2)投影projection(
投影操作是从关系里选取特定的属性列,并且去除重复的元组。设$ R
示例:还是以 Students 关系为例,若要获取所有学生的姓名和学号,操作如下:
-- SQL 示例
SELECT StudentID, Name FROM Students;
在关系代数里,可表示成
(3)连接union(
并操作要求参与运算的两个关系 R 和 S 具有相同的属性列,并且属性的域也相同。它会把两个关系的元组合并,同时去除重复的元组。
示例:假设有两个关系 ClassA 和 ClassB,它们的结构一样,都包含 StudentID 和 Name 字段。若要把两个班级的学生信息合并,操作如下:
-- SQL 示例
SELECT * FROM ClassA UNION SELECT * FROM ClassB;
在关系代数里,可表示成
(4)内连接intersect(
交操作同样要求参与运算的两个关系 R 和 S 具有相同的属性列,并且属性的域也相同。它会返回两个关系中相同的元组。
示例:对于 ClassA 和 ClassB 关系,若要找出同时在两个班级的学生,操作如下:
-- SQL 示例
SELECT * FROM ClassA INTERSECT SELECT * FROM ClassB;
在关系代数里,可表示成
(5)差difference(
差操作要求参与运算的两个关系 R 和 S 具有相同的属性列,并且属性的域也相同。它会返回在关系 R 中但不在关系 S 中的元组。
示例:对于 ClassA 和 ClassB 关系,若要找出只在 ClassA 而不在 ClassB 的学生,操作如下:
-- SQL 示例
SELECT * FROM ClassA EXCEPT SELECT * FROM ClassB;
在关系代数里,可表示成
(6)笛卡尔积product(
笛卡尔积操作会把关系 R 中的每个元组和关系 S 中的每个元组进行组合,形成一个新的关系。新关系的属性列是 R 和 S 的属性列的并集。
示例:假设存在关系 Employees(包含 EmployeeID、EmployeeName)和 Departments(包含 DepartmentID、DepartmentName),若要得到员工和部门的所有可能组合,操作如下:
-- SQL 示例
SELECT * FROM Employees, Departments;
在关系代数里,可表示成
(7)连接join(
连接操作是从两个关系的笛卡尔积中选取满足一定条件的元组。常见的连接类型有等值连接、自然连接等。
等值连接
等值连接是在笛卡尔积的基础上,选取两个关系中指定属性相等的元组。设 R 和 S 是两个关系,A 是 R 的属性,B 是 S 的属性,等值连接可表示为
示例:假设有关系 Orders(包含 OrderID、CustomerID)和 Customers(包含 CustomerID、CustomerName),若要获取订单及其对应的客户信息,操作如下:
-- SQL 示例
SELECT * FROM Orders
JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
在关系代数里,可表示成
自然连接
自然连接是一种特殊的等值连接,它会自动选取两个关系中相同名称的属性进行等值比较,并且去除重复的属性列。
示例:对于上述的 Orders 和 Customers 关系,使用自然连接获取订单及其对应的客户信息,操作如下:
-- SQL 示例
SELECT * FROM Orders NATURAL JOIN Customers;
在关系代数里,可表示成
4.SQL Query
SQL 查询是用来从数据库里获取数据的语句。一个基本的 SQL 查询包含 SELECT、FROM 和 WHERE 子句。
5.Doucument Data Model(NOSQL)
文档数据模型是 NoSQL 数据库里常见的数据模型,数据以文档的形式存储,通常是 JSON、BSON 或者 XML 格式。文档数据库中的文档可以包含嵌套结构,并且不同文档的结构可以不同。
6.Vector Data Model/Mechine Learning Model
向量数据模型是把数据表示成向量的形式,常用于机器学习、信息检索等领域。例如,在文本处理中,可以把文档或者单词表示成向量,通过向量之间的相似度来衡量文档或者单词之间的相关性。
7.SQL简介:
major commands(e.g. select update delete insert);DML,DDL,TCL,DCL
- SELECT:从数据库中选取数据。
select * from Employees;
- UPDATE:更新数据库中的数据。
update empolyees set Salary=6000 where EmployeeID=1;
- DELETE:从数据库中删除数据。
delete from Employees where EmployeeID=1;
- INSERT:向数据库中插入新的数据。
insert into Employees(EmployeeID,Name,Salary) values(2,'Bob',5500);
- 数据操作语言Data Manipulation Language(DML)
DML 用于操作数据库中的数据,主要包括 SELECT、INSERT、UPDATE 和 DELETE 语句。
- 数据定义语言Data Definition Language(DDL)
DDL 用于定义数据库的结构,例如创建、修改和删除数据库对象(如表、视图、索引等)。常见的 DDL 语句有 CREATE、ALTER 和 DROP。
1 | -- 创建一个新的表 |
- 事务控制语言Transaction Control Language(TCL)
TCL 用于管理数据库中的事务,例如提交事务、回滚事务等。常见的 TCL 语句有 COMMIT、ROLLBACK 和 SAVEPOINT。
1 | start transaction; |
- 数据控制语言Data Control Language(DCL)
DCL 用于控制用户对数据库对象的访问权限,例如授予和撤销权限。常见的 DCL 语句有 GRANT 和 REVOKE。
grant select on Employees to 'user'@'localhost'
8.Select Syntax
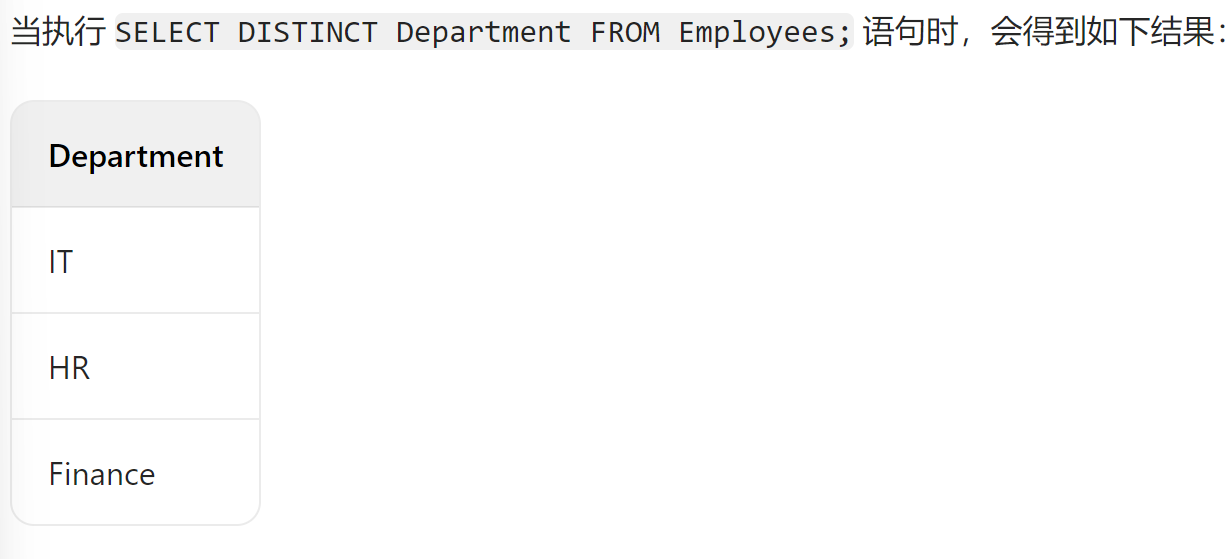
(1)distinct
DISTINCT 关键字用于去除查询结果中的重复行。
select distinct Department from Employees;

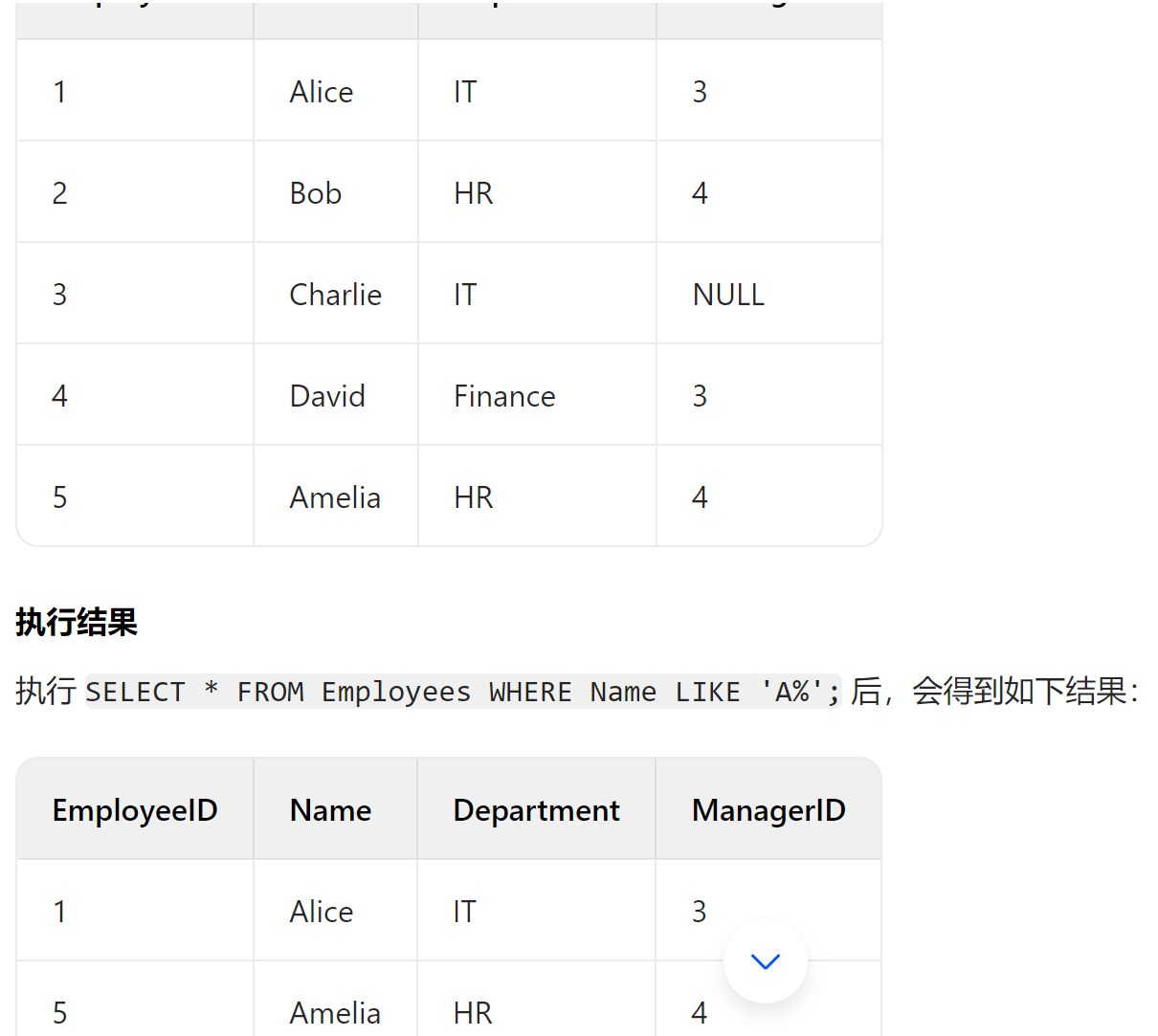
(2)where操作对应有and/or/not,like,is null/is not null等operator操作(is for filtering records)
1 | select * from Employees where Salary>5000 and Department='IT'; |
select * from Employees where Name like 'A%';
这条语句使用了 LIKE 操作符,用于从 Employees 表中筛选出 Name 列以字母 A 开头的所有记录。LIKE 操作符是用于模糊匹配的,% 是通配符,表示任意数量(包括零个)的任意字符。
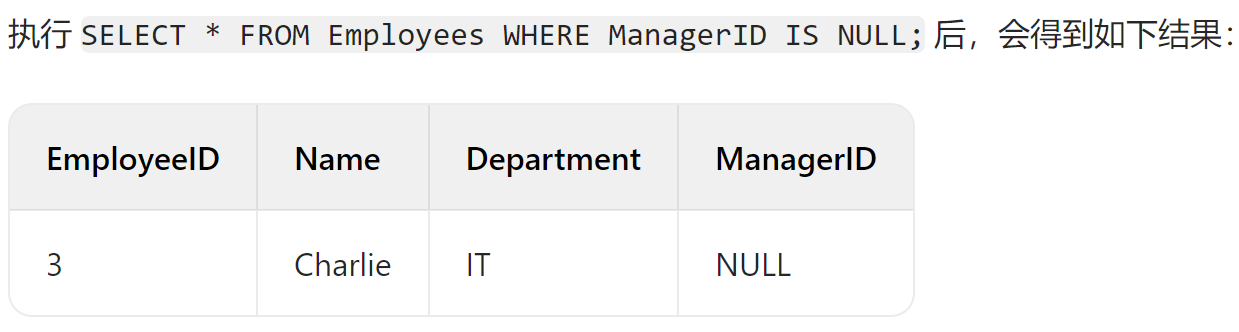
SELECT * FROM Employees WHERE ManagerID IS NULL;
这条语句使用了 IS NULL 操作符,用于从 Employees 表中筛选出 ManagerID 列为 NULL 的所有记录。IS NULL 用于判断某列的值是否为 NULL。
(3)分组group by
GROUP BY 子句用于对查询结果进行分组,通常与聚合函数(如 SUM、AVG、COUNT 等)一起使用。
select Department,count(*) from Employees group by Department;
(4)having(is for filtering aggregated results)
HAVING 子句用于过滤分组后的结果,与 WHERE 子句不同的是,HAVING 子句可以使用聚合函数。
select Department,AVG(Salary) from Employees group by Department having AVG(Salary)>5000
(5)order by
ORDER BY 子句用于对查询结果进行排序,可以按升序(ASC)或降序(DESC)排列。
select * from Employees order by Salary desc;
(6)limit(select top)
LIMIT 关键字(在 MySQL 中)或 SELECT TOP 关键字(在 SQL Server 中)用于限制查询结果的行数。
select * from Employees limit 10;
(7)Alias(AS)
AS 关键字用于为列或表指定别名,使查询结果更易读。
select Name as EmployName,Salary as AnnualSalary from Employees;
(8)join:
(inner)join(also a inner join):returns records that have matching values in both tables,left(outer)join,right(outer)join,full(outer)join,cross join
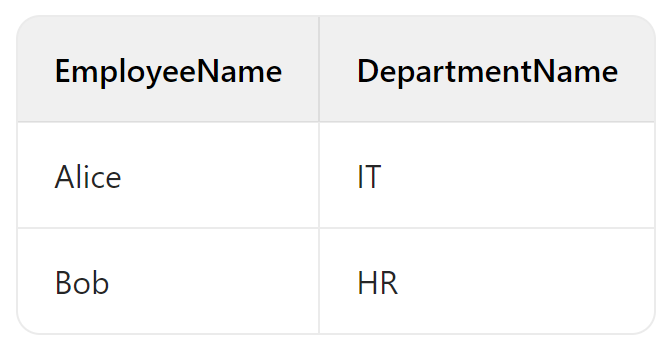
①inner join
INNER JOIN 也被称为简单的 JOIN,它返回两个表中在连接条件上具有匹配值的记录。只有当两个表中指定列的值相等时,对应的行才会被包含在结果集中。
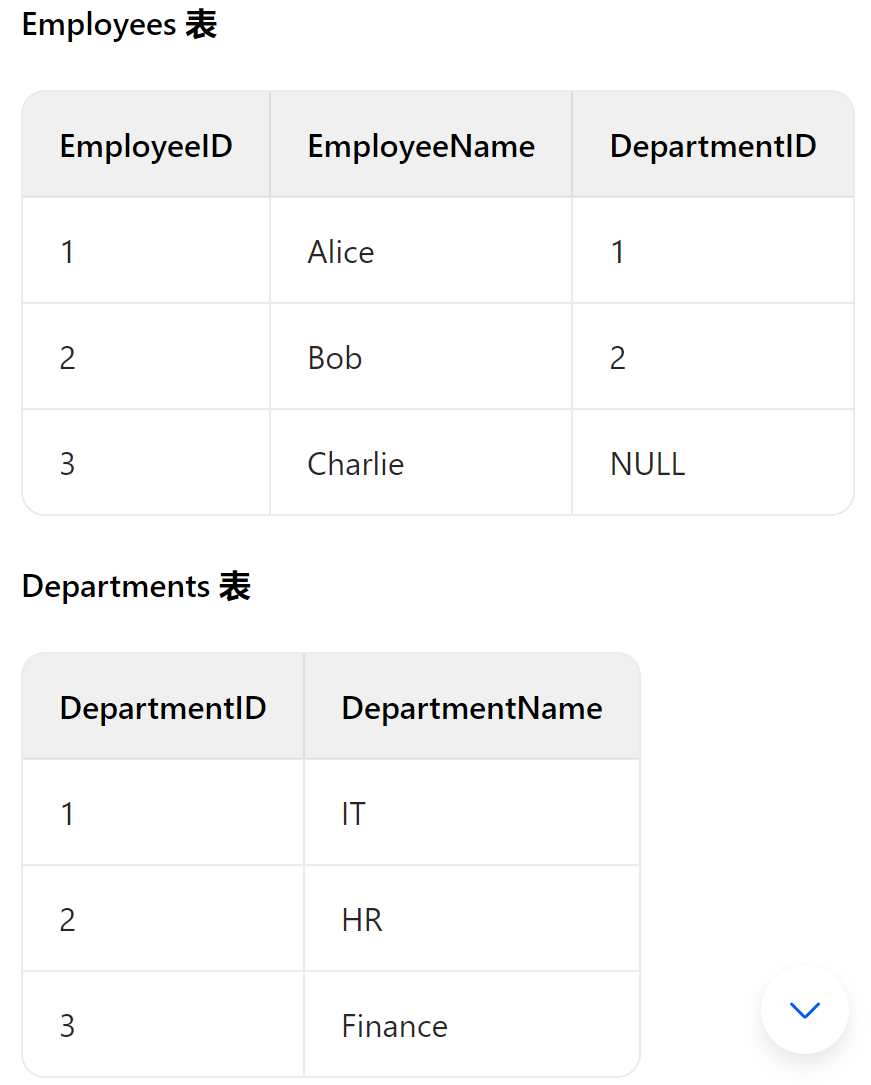
1 | -- 执行 INNER JOIN 查询 |
②left(outer) join(就是保证左表信息全部出来)
LEFT JOIN 会返回左表(FROM 子句中第一个指定的表)中的所有记录,以及右表中匹配的记录。如果右表中没有与左表记录匹配的行,则右表的列值将显示为 NULL。
1 | -- 执行 LEFT JOIN 查询 |
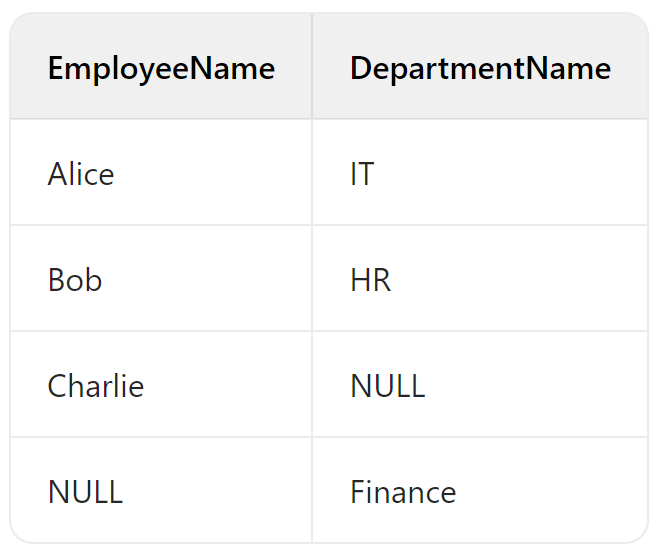
③right join
RIGHT JOIN 与 LEFT JOIN 相反,它返回右表中的所有记录,以及左表中匹配的记录。如果左表中没有与右表记录匹配的行,则左表的列值将显示为 NULL。
1 | -- 执行 RIGHT JOIN 查询 |

④full join
FULL JOIN 返回两个表中的所有记录。如果某一行在另一个表中没有匹配项,则对应的列将显示为 NULL。在 MySQL 中不直接支持 FULL JOIN,但可以使用 UNION 操作来模拟。
1 | -- MySQL 模拟 FULL JOIN |
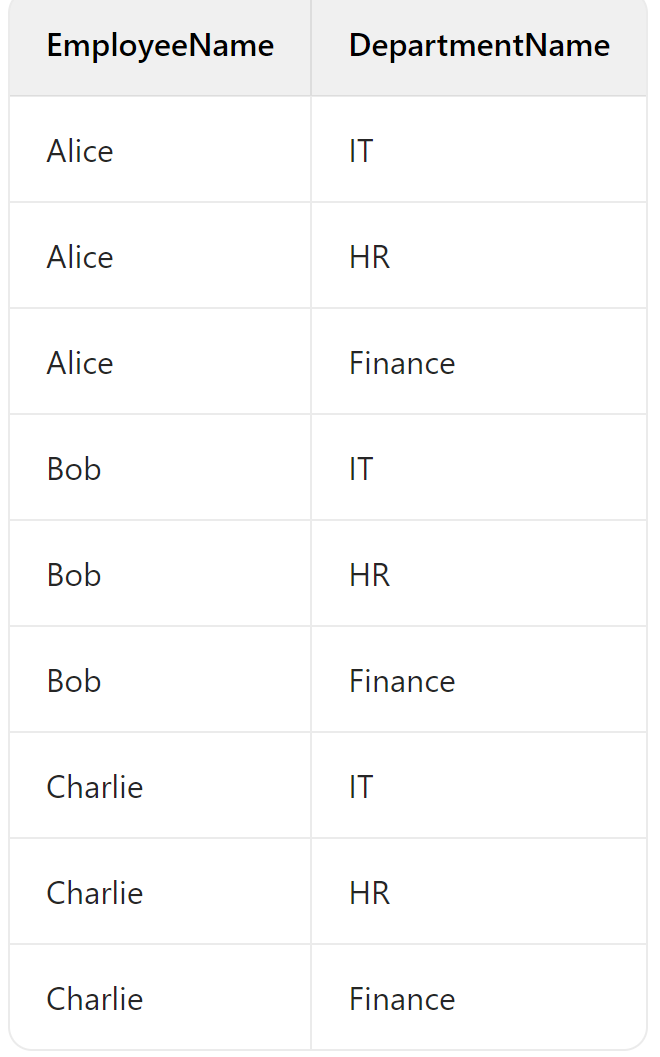
⑤cross join
CROSS JOIN 会生成两个表的笛卡尔积,即左表中的每一行都会与右表中的每一行组合,结果集的行数为左表行数乘以右表行数。
1 | -- 执行 CROSS JOIN 查询 |
不同 JOIN 操作显示信息的说明
在前面的
JOIN查询示例里,EmployeeID和DepartmentID没有显示,是因为在SELECT子句中仅指定了EmployeeName和DepartmentName这两列。SELECT子句的作用是明确要从查询结果里获取哪些列,要是没有在SELECT子句中列出某列,那该列就不会出现在最终的查询结果中。不同的
JOIN操作(如INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN、CROSS JOIN)本身并不决定显示哪些信息,显示的信息完全由SELECT子句来决定。下面是修改后的示例,把EmployeeID和DepartmentID也包含在SELECT子句中。
4.23
1.procedure(存储过程)
存储过程是一组为了完成特定功能的 SQL 语句集,经编译后存储在数据库中。用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
2.case(if-else)
CASE 语句用于在 SQL 中实现条件逻辑,类似于其他编程语言中的 if - else 语句。
1 | -- 根据员工的薪水给出不同的评价 |
3.nested query(sub query)
子查询是指在一个 SQL 查询中嵌套另一个查询。子查询可以出现在 SELECT、FROM、WHERE 等子句中。
1 | -- 查询薪水高于平均薪水的员工 |
4.exists
EXISTS 是一个布尔运算符,用于检查子查询是否返回任何行。如果子查询返回至少一行,则 EXISTS 返回 TRUE,否则返回 FALSE。
1 | select CustomerName |
5.in
IN 运算符用于指定多个可能的值,用于在 WHERE 子句中筛选出符合这些值的记录。
1 | -- 查询部门 ID 为 1 或 2 的员工 |
6.insert into
INSERT INTO 语句用于向表中插入新记录。
insert into Employees(EmployeeName,DepartmentID) values ('Eve','2');
7.update
UPDATE 语句用于修改表中的现有记录。
update set where
1 | update Customers |
8.delete
DELETE 语句用于从表中删除记录。
delete from Employees where DepartmentID=3;
DML has ended
9.DDL(数据定义语言) review
DDL 用于定义数据库的结构和对象,常见的 DDL 语句有 CREATE、ALTER 和 DROP。
10.numeric data types(数值数据类型)
(1)int or integer
用于存储整数,通常占用 4 个字节,范围根据数据库系统略有不同。
(2)smallint
用于存储较小的整数,通常占用 2 个字节,范围比 int 小。
(3)decimal(p,s)
用于存储精确的小数,p 表示精度(总位数),s 表示小数位数。
(4)float
用于存储单精度浮点数,通常占用 4 个字节,精度有限。
(5)double
用于存储双精度浮点数,通常占用 8 个字节,精度比 float 高。
1 | -- 创建一个包含不同数值类型的表 |
11.text data type(文本数据类型)
(1)char(n)
用于存储固定长度的字符串,n 表示字符串的长度。如果存储的字符串长度小于 n,则会用空格填充。
(2)varchar(n)
用于存储可变长度的字符串,n 表示字符串的最大长度。只占用实际存储的字符串长度的空间。
(3)text
用于存储大量的文本数据,长度没有固定限制。
1 | create table TextTable( |
12.constraints
(1)not null
确保列中不允许存储 NULL 值。
(2)unique
确保列中的值是唯一的。
(3)default
为列指定默认值,如果插入记录时没有提供该列的值,则使用默认值。
(4)check
用于限制列中的值必须满足指定的条件。
1 | -- 创建一个包含约束的表 |
13.auto increment
AUTO_INCREMENT 用于为表中的某一列自动生成唯一的整数序列,通常用于主键列。
AUTO_INCREMENT 是数据库中的一个重要特性,主要用于为表中的某一列自动生成唯一的整数序列,通常与主键列搭配使用。每当向表中插入一条新记录时,该列的值会自动递增。在 MySQL 里,一个表只能有一个 AUTO_INCREMENT 列,并且该列必须被定义为主键或者包含在一个唯一索引里。以下是创建带有 AUTO_INCREMENT 列的表的示例:
1 | create table users( |
14.foreign key straint(外键约束)
child table and parent table
外键约束用于在两个表之间建立关联,关联的表分别称为子表(child table)和父表(parent table)。父表包含主键列,子表包含引用父表主键的外键列。外键约束保证了数据的引用完整性,也就是子表中的外键值必须与父表中主键值相匹配,或者为 NULL。以下是创建带有外键约束的表的示例:
1 | --- 创建父表 |
15.referential action(引用操作)
当父表中的记录被更新或者删除时,引用操作决定了子表中的相关记录要如何处理。常见的引用操作有以下几种:
(1)cascade(级联)
当父表中的记录被更新或者删除时,子表中所有引用该记录的外键值也会被相应地更新或者删除。示例如下:
1 | create table employees( |
(2)set null
当父表中的记录被更新或者删除时,子表中所有引用该记录的外键值会被设置为 NULL。不过,这要求外键列允许为 NULL。示例如下:
1 | create table employees( |
(3)restrict
在父表中有相关记录被子表引用时,禁止对父表中的记录进行更新或者删除操作。这是默认的引用操作。示例如下:
1 | create table employees( |
16.index(索引)(节约搜索时间提高搜索效率)
create index
索引是一种数据结构,它能够加快数据库表中数据的查询速度。通过创建索引,数据库可以更快地定位到满足查询条件的记录,从而节省搜索时间,提高搜索效率。不过,索引并非适用于所有场景:
- 频繁更新:在对表进行频繁更新操作时,索引也需要相应地更新,这会降低更新操作的性能。
- 数据量小:当表中的数据量较小时,专门创建索引的开销可能会超过索引带来的性能提升,因此没必要专门建立索引。
1 | create index idx_name on table_name (column1, column2,...); |
17.sql view(视图)
视图是一个虚拟表,它并不实际存储数据,而是基于一个或多个表的查询结果。视图可以简化复杂的查询,提高数据的安全性,并且允许用户以不同的方式查看数据。创建视图的语法如下:
1 | create view view_name as |
18.alter value(修改表结构)
ALTER TABLE 语句用于修改已存在表的结构,常见的操作有以下几种:
(1)alter table add
用于向表中添加新的列。示例如下:
1 | alter table users add column phone varchar(20); |
(2)alter table modify
用于修改表中现有列的定义,例如修改列的数据类型。示例如下:
1 | alter table users modify column phone varchar(30); |
(3)alter table drop
用于删除表中的列。示例如下:
1 | alter table users drop column phone; |
19.transaction(事务)
事务是一组不可分割的数据库操作序列,这些操作要么全部执行成功,要么全部不执行。事务具有原子性、一致性、隔离性和持久性(ACID)四个特性。常见的事务操作有以下几种:
(1)commit
用于提交事务,将事务中所做的所有修改永久保存到数据库中。示例如下:
1 | start transaction; |
(2)rollback
用于回滚事务,撤销事务中所做的所有修改。示例如下:
1 | start transaction; |
(3)savepoint
用于在事务中设置保存点,允许在事务执行过程中部分回滚。示例如下:
1 | start transaction; |
数据库是如何发现错误进行回滚的?
数据库发现错误并触发回滚的机制主要依赖于==事务控制逻辑和错误检测机制==
数据库通过 应用层主动检测 和 数据库层自动检测 两种方式发现错误:
一、错误发现的途径
应用层主动检测(业务逻辑层面)
- 应用程序在执行数据库操作前或后,通过业务规则判断是否出现异常(例如:转账时余额不足、数据格式不符合要求等)。
- 若检测到错误(如代码中通过条件判断、异常捕获等逻辑),应用会主动调用数据库的回滚接口(如
ROLLBACK或ROLLBACK TO SAVEPOINT),显式触发回滚。数据库层自动检测(约束与系统层面)
- 完整性约束违反:数据库内置的约束(如主键唯一性、外键引用、CHECK 约束、非空约束等)会在数据操作时自动校验。若违反约束(例如插入重复主键、外键引用不存在的记录),数据库会立即抛出错误(如 SQL 错误码)。
- 系统错误:数据库在执行操作时遇到内部错误(如磁盘空间不足、事务超时、锁冲突等),会自动生成错误信号并中断事务。
二、回滚机制的核心原理
当错误被检测到后,数据库通过 事务日志(Transaction Log) 和 保存点(Savepoint) 实现回滚,具体逻辑如下:
- 事务日志的作用
- 数据库在事务执行过程中,会将每一步操作(如插入、更新、删除)记录到 撤销日志(Undo Log) 中,记录数据修改前的原始状态。
- 回滚时,数据库根据撤销日志逆向执行操作,将数据恢复到错误发生前的状态(例如:对
UPDATE操作,回滚会将数据恢复为修改前的值)。- 完全回滚与部分回滚
- 完全回滚(
ROLLBACK):撤销事务开始后所有未提交的操作,将整个事务回退到初始状态(即START TRANSACTION之前的状态)。- 部分回滚(
ROLLBACK TO SAVEPOINT):通过SAVEPOINT在事务中标记一个中间点,回滚时仅撤销该保存点之后的操作,保存点之前的操作仍保留(需后续通过COMMIT提交)。- 事务原子性的保证
- 无论错误是由应用层还是数据库层触发,事务的原子性要求确保:要么所有操作都提交,要么所有未提交的操作都被回滚,避免数据处于中间状态。
20.motivation(动机)
在数据库设计和开发中,运用上述这些特性和技术主要有以下几个动机:
- 数据完整性:利用
AUTO_INCREMENT、外键约束和引用操作可以保证数据的完整性和一致性,防止出现无效或者不一致的数据。 - 性能优化:使用索引能够提高查询性能,尤其是在处理大量数据时,能够显著缩短查询时间。
- 灵活性和可维护性:视图和
ALTER TABLE语句可以让数据库结构更加灵活,便于后续的维护和扩展。 - 数据安全性:事务机制可以确保在并发操作时数据的安全性和一致性,避免数据冲突和错误。
## 4.24
1.sanitize input(输入净化)
输入净化是一种重要的安全措施,主要用于防止恶意用户通过输入特殊字符或代码来攻击数据库,像 SQL 注入攻击。在将用户输入的数据用于数据库查询之前,需要对输入进行处理,过滤掉可能导致安全问题的字符或代码。例如,在使用 Python 的 sqlite3 库时,可以使用参数化查询,它会自动对输入进行净化:
1 | import sqlite3 |
2.prevention(预防)
预防在数据库安全和性能优化方面都非常关键。主要包括以下几个方面:
- 安全预防:通过输入净化、访问控制、加密等手段,防止 SQL 注入、跨站脚本攻击(XSS)、数据泄露等安全问题。
- 性能预防:合理设计数据库结构、创建适当的索引、优化查询语句等,避免出现性能瓶颈,如查询缓慢、死锁等问题。
3.ORM: Object-Relational Mapping(对象关系映射)
对象关系映射(ORM)是一种编程技术,它允许开发者使用面向对象的方式来操作数据库,而无需编写原生的 SQL 语句。ORM 框架会自动将对象的操作转换为相应的 SQL 语句,从而简化了数据库开发过程。例如,在 Python 中使用 SQLAlchemy 这个 ORM 框架:
1 | from sqlalchemy import Column, Integer, String, create_engine |
4.ER Model
实体 - 关系模型是一种用于数据库设计的概念模型,它通过实体、属性、关系等元素来描述现实世界中的数据及其关系。
(1)Entities(实体)
实体是现实世界中可区别的事物或对象,例如学生、课程、员工等。在 ER 图中,实体通常用矩形表示。
(2)Attributes:the details about each thing(属性)
属性是实体的特征或描述信息,例如学生的姓名、年龄、学号等。在 ER 图中,属性通常用椭圆形表示,并与对应的实体相连。
(2)Relations(can also have attributes)(关系)
关系表示实体之间的联系,例如学生和课程之间的选课关系、员工和部门之间的所属关系等。在 ER 图中,关系通常用菱形表示,并与相关的实体相连。关系也可以有自己的属性,例如选课关系可以有成绩这个属性。
(3)Participation(total,partical participation)(参与度)
参与度描述了实体在关系中出现的情况,分为完全参与和部分参与:
- 完全参与(Total Participation):表示实体集中的每个实体都必须参与到某个关系中。在 ER 图中,用双线表示。
- 部分参与(Partial Participation):表示实体集中的部分实体参与到某个关系中。在 ER 图中,用单线表示。
(4)generalization and specialization(泛化与特化)
- Generalization(泛化):是从多个具体实体中抽象出共同特征,形成一个更通用的实体。例如,从本科生、研究生中抽象出学生这个通用实体。
- Specialization(特化):是将一个通用实体根据某些特征细分为多个具体实体。例如,将学生实体细分为本科生、研究生。
(5)weak entities(弱实体)
弱实体是依赖于其他实体(称为强实体)而存在的实体,它没有自己的主键,而是通过与强实体的关系来确定其唯一性。例如,订单明细依赖于订单而存在,订单明细就是一个弱实体。在 ER 图中,弱实体用双矩形表示。
(6)ternary relationships(三元关系)
三元关系是指三个实体之间的关系。例如,教师、课程和学生之间的关系,一个教师可以教授多门课程,一门课程可以有多个学生选修,一个学生可以选修多门课程。在 ER 图中,三元关系用菱形表示,并与三个相关的实体相连。
4.29
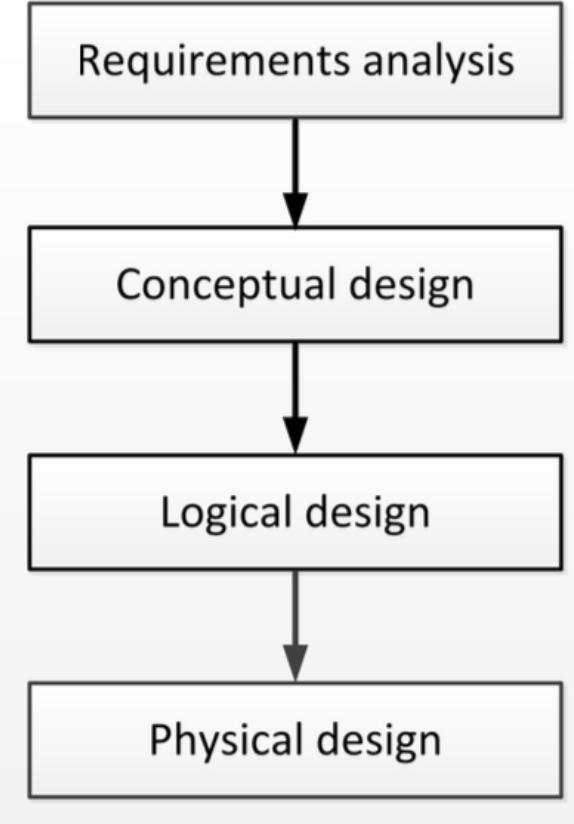
1.Database Design
需求分析->概念设计->逻辑设计->物理设计
2.ER图常见物象
(1)Entities实体
表示存储有关某个事物的数据的真实对象或概念,表示为矩形
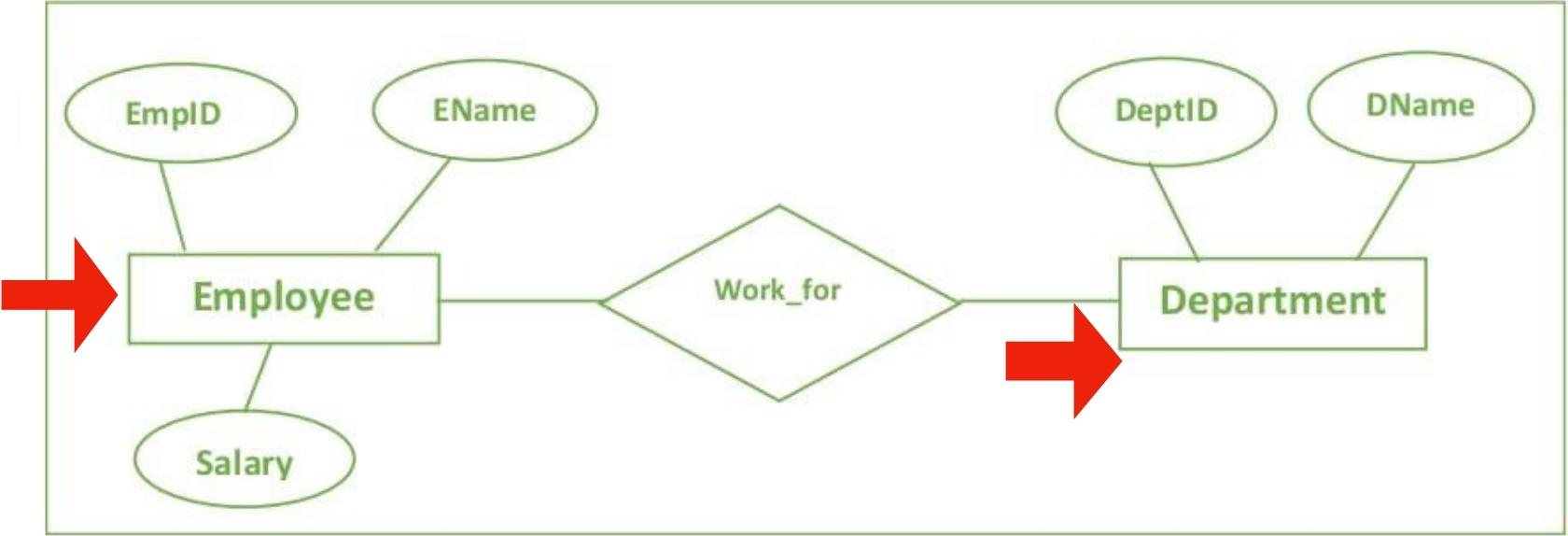
(2)Attributes属性
是实体的具体特征,如员工实体可能有ID,姓名,薪水等属性;属性可以是简单的,复合的,派生的,多值的(多个东西实际上对应一种名字,只是名头不一样),表示为连接到实体的椭圆
(3)Relationships关系
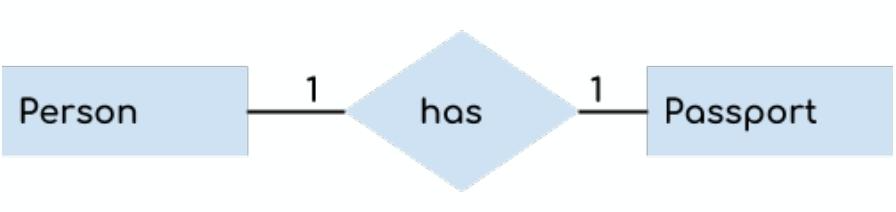
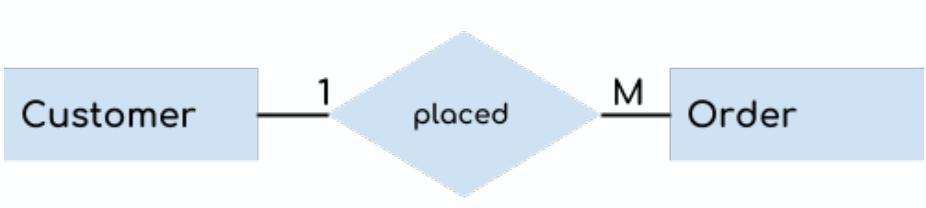
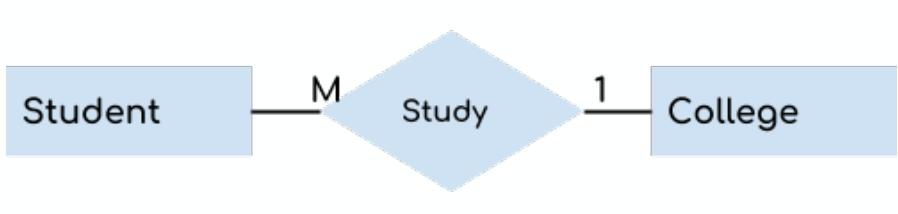
关系是实体之间的关联,例如员工“works in”部门,分为1:1(一对一,如一个人have一张机票),1:M(一对多,如一个老师teach多个学生),M:N(多对多哦,如一个学生enroll注册多个课程,一个课程有多个学生)

(4)Participation参与
参与是确认是否所有实体都得有这个关系,表示为不同形式的连线。如果每个实体都需要参与就画double line双实线,有些可能不参与就画single line单实线。例如每位学生必须enroll注册至少一门课程,而不是所有课程都必须被enroll

(5)Keys键
primary keys主键就在实体的名称下面加下划线(are underlined)
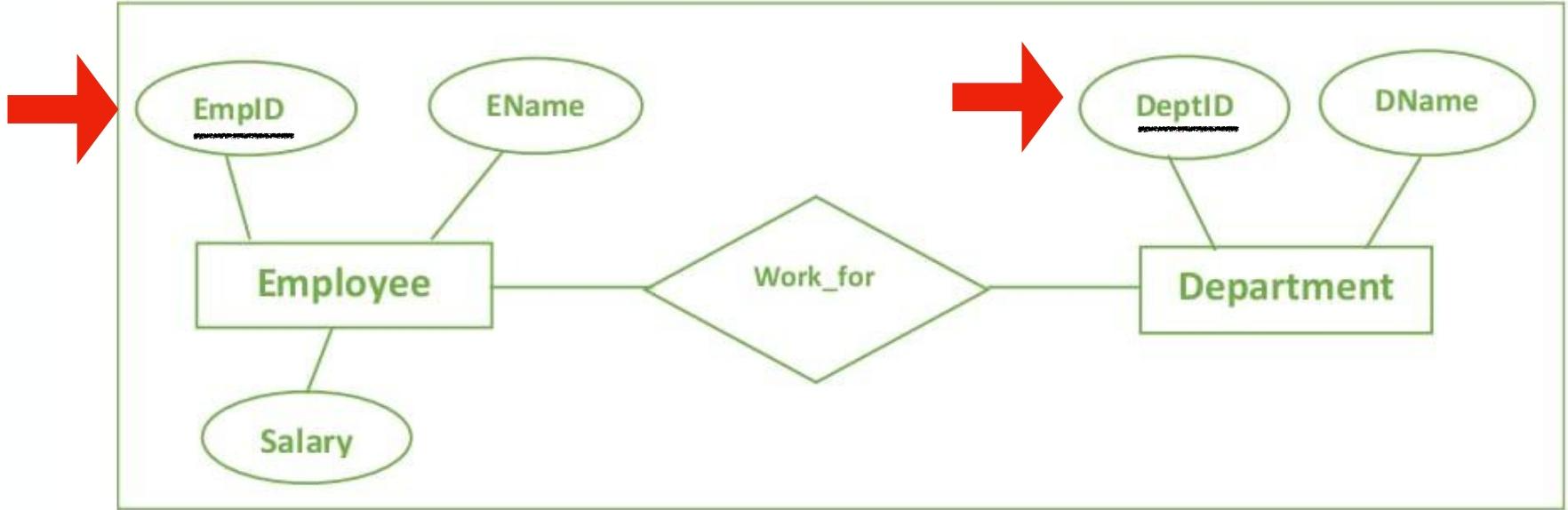
(5)Generalization&Specialization泛化和专业化:grouping similar things
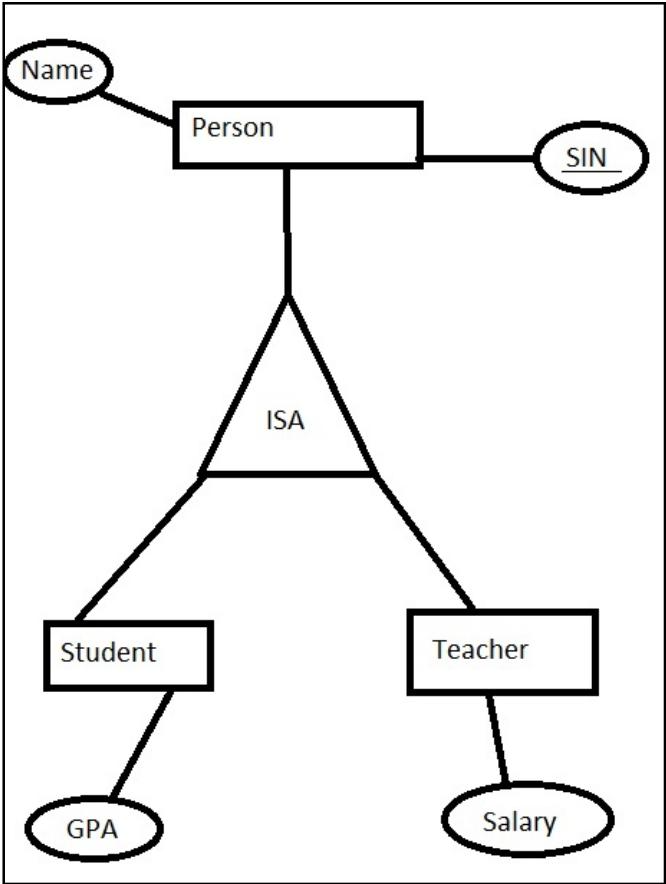
Generalization泛化:当几个实体相似时,我们可以将它们归类为一个通用类型
Specialization特化:将一般实体拆分为更具体的子实体
Inheritance继承:子实体从通用化实体继承属性和关系
三角形标注ISA表示继承,如学生和老师继承人的属性
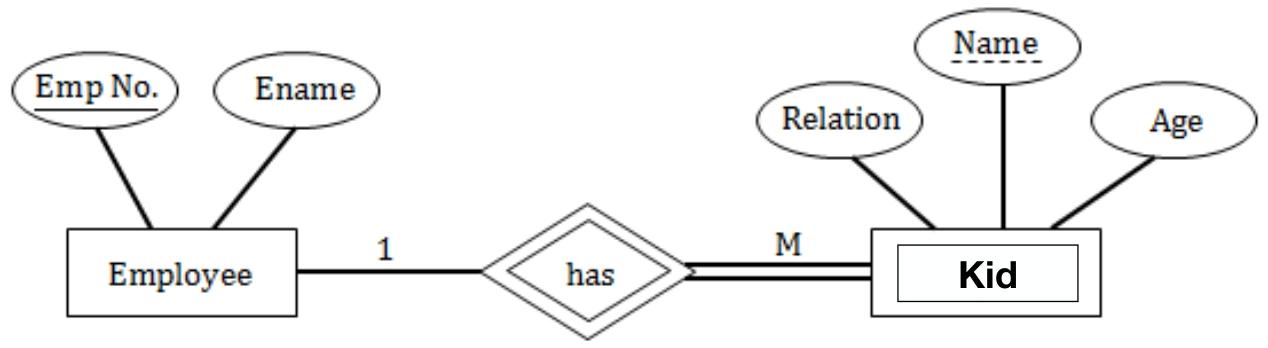
(6)Weak Entities弱实体
弱实体依附于其他实体存在,否则将无意义。表示为双矩形。实体与弱实体间的关系表示为双菱形,又称identity relationship标识关系
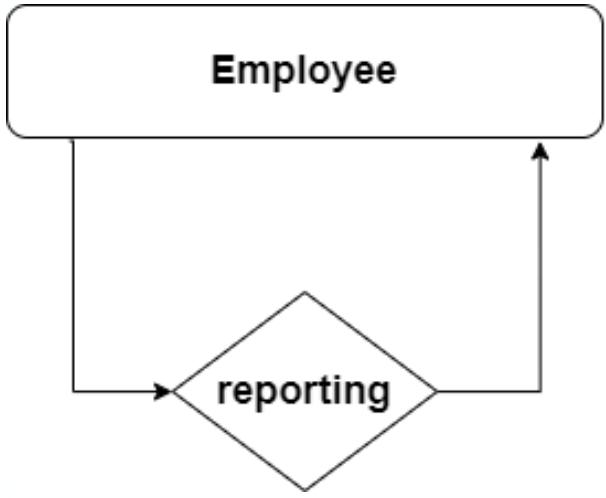
(7)Recursive Relationship递归关系
指实体内部之间有交互动作,用循环箭头表示
如alicebob都是员工,员工bob要向经理(也算employee)的alice汇报工作
(8)Ternary Relationships三元关系
•同时涉及三个实体的关系。你不能只看两个来完全理解这种关系。
• Example: A member want to reserves some equipment at a certain time frame. who? what? when?
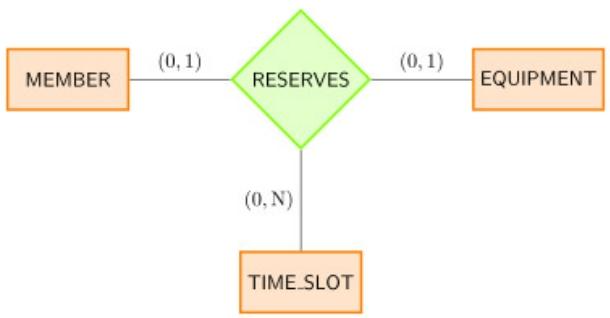
(9)(Min,Max)大小限制
• (min, max) 表示法告诉我们实体可以参与关系的次数 - 至少 (min) 和最多 (max)。• 任何人都可以注册课程,但最多可容纳 50 人。

3.ER图绘制流程
(1)Mapping of Regular Entity Types(常规实体类型的映射)
将每个常规实体类型转换为一个关系模式,实体的属性成为关系模式的属性,实体的主键作为关系模式的主键。例如,“学生” 实体(属性:学号、姓名、年龄,学号为主键)映射为 “学生表”,包含这些属性且学号为主键。
(2)Mapping of Weak Entity Types(弱实体类型的映射)
弱实体依赖强实体存在,无独立主键。映射时,弱实体与所依赖强实体的主键共同构成其关系模式的主键。如 “订单明细”(弱实体)依赖 “订单”(强实体),订单号(订单主键) + 明细项编号可作为订单明细表的主键,同时包含弱实体自身属性。
(3)Mapping of Binary 1:1 Relationship Types(二元一对一关系类型的映射)
可将关系合并到任一端实体的关系模式中(如作为一个属性),或单独创建关系模式(包含两端实体主键及关系自身属性,若有)。例如,“部门” 与 “经理”(1:1),可将经理主键加入部门表,或新建表包含部门与经理主键。
(4)Mapping of Binary 1:N Relationship Types(二元一对多关系类型的映射)(对于1:N来说,就是要在动作的接收者那加一个动作发出者的主键作为外键放后面即可)
将一端(1 端)实体的主键加入多端(N 端)实体的关系模式中。如 “部门”(1 端)与 “员工”(N 端),把部门编号(部门主键)加入员工表作为外键,体现一对多关系。
(5)Mapping of Binary M:N Relationship Types(二元多对多关系类型的映射)(对于M:N,就是要新建一个表table名字为动作的名字,然后表中让动作发出接受者的主键作为外键,这样就能形成m:n的关系)
需创建新关系模式,包含两端实体主键及关系自身属性(若有)。例如 “学生” 与 “课程”(多对多),创建 “选课表”,包含学生学号、课程编号,还可含成绩等属性。
(6)Mapping of Multivalued attributes(多值属性的映射)
多值属性(如一个人多个电话号码)不能直接存于关系模式,需新建关系模式。如创建 “电话表”,包含个人主键与电话号码属性。
(7)Mapping of Ternary Relationship(三元关系的映射)
创建新关系模式,包含三个实体的主键及关系自身属性(若有)。例如 “供应商 - 项目 - 零件” 的供应关系,创建表包含供应商编号、项目编号、零件编号,以及供应数量等属性。
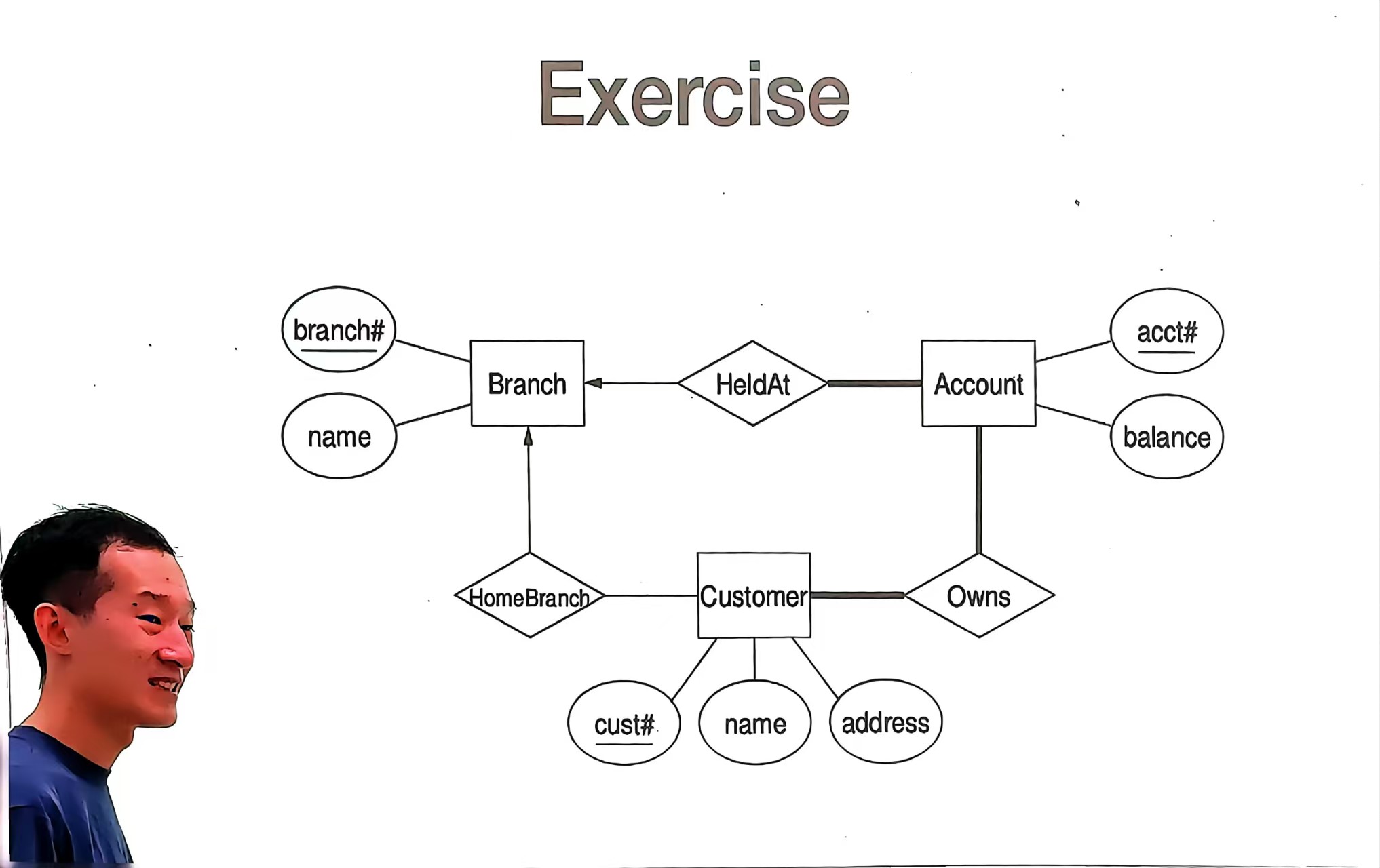
如何解读ER图?
- 长方形(实体)
(1)Branch(分行):代表银行分行这一实体,具有属性
branch#(分行编号,下划线表示主键,唯一标识分行)和name(分行名称)。(2)Account(账户):代表银行账户实体,属性有
acct#(账户编号,主键)和balance(账户余额)。(3)Customer(客户):代表银行客户实体,属性包括
cust#(客户编号,主键)、name(客户姓名)和address(客户地址)。
- 菱形(关系)
(1)HeldAt(开设在):表示账户(Account)与分行(Branch)之间的关系,即账户开设在某个分行。
(2)HomeBranch(归属分行):描述客户(Customer)与分行(Branch)的关系,即客户的归属分行。
(3)Owns(拥有):体现客户(Customer)与账户(Account)的关系,即客户拥有账户。
- 椭圆形(属性)
椭圆形用于表示实体的特征,如
branch#、name是Branch实体的属性;acct#、balance是Account实体的属性;cust#、name、address是Customer实体的属性。
- 连线粗细与箭头
(1)图中
Account到HeldAt的连线较粗,通常在 ER 图中,这种视觉差异可能用于强调关系的重要性或突出显示特定关联,但并非严格的标准规范。(2)箭头表示关系的方向或参与度。例如,
HeldAt到Branch的箭头,表明Account通过HeldAt关系指向Branch,即账户开设在分行,一个账户只对应一个分行(从图中关系方向看,体现了一种单向的关联指向)。而Owns关系连接Customer和Account无箭头,暗示这是一种多对多的关系(一个客户可拥有多个账户,一个账户可被多个客户拥有)。
如何作答“如何解读ER图”的问题?
[!success]
解读此 ER 图时,答案应包含以下信息:图中的实体及其属性、实体间的关系、关系的含义、主键标识(下划线)等。
图中包含三个实体:
- Branch(分行):具有属性
branch#(分行编号,主键,以下划线标识)和name(分行名称)。- Account(账户):具有属性
acct#(账户编号,主键)和balance(账户余额)。- Customer(客户):具有属性
cust#(客户编号,主键)、name(客户姓名)和address(客户地址)。实体间的关系如下:
- HeldAt(开设在):表示
Account(账户)与Branch(分行)的关系,即账户开设在某个分行。- Owns(拥有):表示
Customer(客户)与Account(账户)的关系,即客户拥有账户。- HomeBranch(归属分行):表示
Customer(客户)与Branch(分行)的关系,即客户的归属分行。通过这些元素,该 ER 图构建了一个简单的银行相关数据模型,清晰展示了分行、账户、客户及其属性与相互关系,为后续数据库设计(如关系模式转换)提供了概念基础。
4.Heuristic Guideline(启发式准则)
(1)Heuristic Guideline 1
- 内容:关系中的每个元组应代表一个实体或关系实例,且仅通过外键引用其他实体。不同实体(如学生、课程)的属性不应混合在同一关系中。
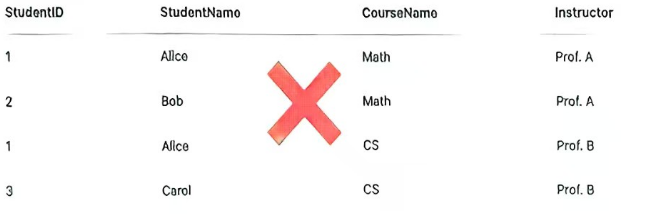
- 示例:图中表格将
StudentID(学生编号)、StudentName(学生姓名)、CourseName(课程名称)、Instructor(教师)混合,这种设计不符合准则,被标记为错误(打叉)。
将这些属性放在同一表中,会使关系语义混乱,违背 “一个关系代表一种实体或关系实例” 的原则。例如,该表既想表示学生信息,又想表示课程信息,导致元组含义不清晰,因此被标记为错误。
(2)Heuristic Guideline 2
- 内容:避免冗余信息。冗余信息可能导致更新不一致。
- 示例:若数学课程的教师
Prof. A被Prof. X取代,由于教师信息在每个学生 - 课程对中重复存储,若未更新所有相关行,会导致数据冲突或错误。
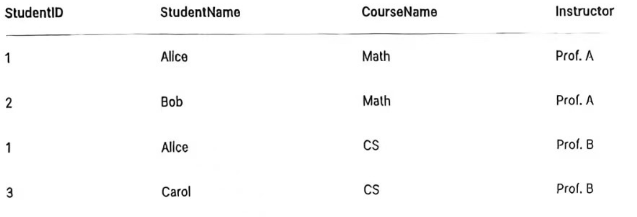
不能把Prof.A变成Prof.X
(3)Heuristic Guideline 3
- 内容:设计的模式应避免插入、删除和更新异常。
- 示例:对于
EMP_PROJ(Emp#, Proj#, Ename, Pname, No_hours)表,删除一个项目会误删所有参与该项目的员工;若一个员工是某项目的唯一参与者,删除该员工会误删项目,这就是删除异常。
(4)Heuristic Guideline 4
- 内容:关系设计应使元组的
NULL值尽可能少。NULL会导致歧义(未知还是不适用),并使查询复杂易错。 - 示例:查询考试不及格的学生时,需添加
grade is not null条件,因为grade为NULL不代表不及格,体现了NULL对查询的影响。
(5)Heuristic Guideline 5
- 内容:设计关系模式时,应能通过适当相关的属性(主键、外键)对的相等条件进行连接,以抑制虚假元组产生。若表间无匹配键属性或值不一致,连接会出错或产生虚假结果。
- 核心:确保表间通过合理的键(如主键 - 外键)关联,避免连接错误或无效结果。
5.Database Normalization
数据库规范化通过将大表拆分为更小的相关表,并使用键定义它们之间的清晰关系,以减少数据冗余、消除异常(插入、删除、更新异常)。规范化遵循一系列范式(Normal Forms):
(1)1NF(First Normal Form)第一范式
表中无重复组或数组,所有列值为原子值(不可再分)。
-
原子性:每列值为不可分割的最小单元(如字符串、数字,而非列表 / 集合)。
-
数据类型一致性:每列仅存储单一类型的值。
-
非 1NF 表
(旧 users 表):
-
| userid | fullname |
| ---------------------------------------- | ---------- |
| 1 | John Doe |
| 2 | Mary Smith |
|fullname包含空格分隔的姓名,非原子值。 | | -
1NF 表
(新 users 表):
| userid | firstname | lastname |
| ------------------------------ | --------- | -------- |
| 1 | John | Doe |
| 2 | Mary | Smith |
| 姓名拆分为独立列,符合原子性。 | | |
每个格子只能装 “单一数据”,不能 “抱团”:表中的每个 “单元格” 只能存一个 独立、不可分割 的值,不能存 “一堆数据”。
比如:“姓名” 列不能存 “张三 李四”(两个人名挤一起),也不能存 “张 / 三”(用斜线分隔),必须拆成 “姓” 和 “名” 两列。
再比如:“课程” 列不能写 “数学,物理”(多个课程用逗号隔开),这属于 “重复组”,要么拆成多行(每个课程一行),要么单独建 “选课表”。
目的:让表看起来 “干干净净”,每个格子都规规矩矩只存一个值,方便后续操作。
反例
(非 1NF):
| 学生 ID | 姓名 | 课程 |
| ------- | -------- | ---------- |
| 1 | 张三李四 | 数学,物理 |正例
(1NF):
| 学生 ID | 姓 | 名 | 课程 |
| ------- | ---- | ---- | ---- |
| 1 | 张 | 三 | 数学 |
| 1 | 张 | 三 | 物理 |
(2)2NF(Second Normal Form)
满足 1NF,且每个非键列完全函数依赖于主键(无部分依赖)。
- 先满足 1NF。
- 完全函数依赖:非主键列依赖于整个主键(若主键为复合键,不能仅依赖部分键)。
非 2NF 表(Students 表):
| IDSt | LastName | IDProf | Prof |
| ------------------------------------------------------------ | -------- | ------ | ------ |
| 1 | Mueller | 3 | Schmid |
| 主键为(IDSt, IDProf),但Prof仅依赖IDProf,存在部分依赖。 | | | |
2NF 表(分解后):
-
Students 表:
| IDSt | LastName |
| ---- | -------- |
| 1 | Mueller | -
Professors 表:
| IDProf | Prof |
| ---------------------------------- | ------ |
| 3 | Schmid |
| 消除部分依赖,非键列完全依赖主键。 | |
2NF(第二范式):非主键列必须 “全靠主键”,不能 “只靠一半”
前提:先满足 1NF,且表有 主键(可能是单个字段,也可能是多个字段的 “复合主键”)。
核心规则:表中 “非主键列” 必须完全依赖整个主键,不能只依赖主键的“一部分”。
- 比如:主键是 “学生 ID + 课程 ID”(复合主键,唯一标识一个学生选的一门课),但 “学生姓名” 只依赖 “学生 ID”,“课程名称” 只依赖 “课程 ID”。这时候 “学生姓名” 和 “课程名称” 只依赖主键的 “一半”,属于 “部分依赖”,不符合 2NF。
解决办法:把 “只依赖一半主键” 的字段拆出去,单独建表。
原表(非 2NF):
| 学生 ID | 课程 ID | 学生姓名 | 课程名称 | 成绩 |
| ------- | ------- | -------- | -------- | ---- |
| 1 | 101 | 张三 | 数学 | 90 |拆分成三张表(2NF):
学生表(主键:学生 ID):
| 学生 ID | 学生姓名 |
| ------- | -------- |
| 1 | 张三 |课程表(主键:课程 ID):
| 课程 ID | 课程名称 |
| ------- | -------- |
| 101 | 数学 |选课表(主键:学生 ID + 课程 ID):
| 学生 ID | 课程 ID | 成绩 |
| ------- | ------- | ---- |
| 1 | 101 | 90 |目的:避免 “部分依赖” 导致的数据冗余(比如同一个学生姓名在多个课程记录中重复出现)。
(3)3NF(Third Normal Form)
满足 2NF,且无非主属性对主键的传递依赖。
- 先满足 2NF。
- 无传递依赖:非主属性仅依赖于候选键,不依赖于其他非主属性。
非 3NF 表(Vendor 表):
| ID | Name | Account No | Bank Code No | Bank |
| ------------------------------------------------------------ | ------- | ---------- | ------------ | ------ |
| 1 | Vendor1 | 12345 | B001 | Bank A |
| Bank依赖于Bank Code No,而Bank Code No依赖于ID,存在传递依赖。 | | | | |
3NF 表(分解后):
-
Vendor 表:
| ID | Name | Account No | Bank Code No |
| ---- | ------- | ---------- | ------------ |
| 1 | Vendor1 | 12345 | B001 | -
Bank 表:
| Bank Code No | Bank |
| ------------------------------------ | ------ |
| B001 | Bank A |
| 消除传递依赖,非主属性仅依赖候选键。 | |
3NF(第三范式):非主键列之间不能 “间接依赖”,只能 “直接靠主键”
前提:先满足 2NF。
核心规则
:表中 “非主键列” 之间不能存在
传递依赖
,即不能有 “字段 A → 字段 B → 字段 C” 这种间接依赖关系,字段 C 必须直接依赖主键,而不是依赖另一个非主键字段。
- 比如:员工表中有 “员工 ID(主键)、部门 ID、部门名称”,“部门名称” 依赖 “部门 ID”,而 “部门 ID” 依赖 “员工 ID”,形成 “员工 ID → 部门 ID → 部门名称” 的传递依赖,不符合 3NF。
解决办法
:把 “传递依赖” 的字段拆出去,单独建表。
原表(非 3NF):
| 员工 ID | 部门 ID | 部门名称 | 员工姓名 |
| ------- | ------- | -------- | -------- |
| 1 | D01 | 人事部 | 张三 |拆分成两张表(3NF):
员工表(主键:员工 ID):
| 员工 ID | 部门 ID | 员工姓名 |
| ------- | ------- | -------- |
| 1 | D01 | 张三 |部门表(主键:部门 ID):
| 部门 ID | 部门名称 |
| ------- | -------- |
| D01 | 人事部 |目的:避免 “传递依赖” 导致的更新异常(比如修改部门名称时,需要更新所有相关员工记录,容易漏改)。
[!success]
一句话总结三个范式的关系
- 1NF:先让每个格子 “单身”(只存一个值)。
- 2NF:再让非主键列 “全靠主键”(不能只依赖主键的一部分)。
- 3NF:最后让非主键列 “直接靠主键”(不能绕弯子依赖其他非主键列)。
(4)BCNF(Boyce-Codd Normal Form)(Boyce 和 Codd 是两个人的姓氏,分别是 Raymond F. Boyce 和 Edgar F. Codd(数据库领域的大佬,Codd 还是关系型数据库的创始人,提出了关系模型和前三范式)
3NF 的严格版本,每个决定因素(Determinant)均为候选键。
- BCNF:所有 “决定因素” 都必须是候选键,包括主键和其他候选键,杜绝任何非候选键决定其他字段的情况(哪怕是主属性之间的依赖)。
若存在函数依赖
解决 3NF 中可能存在的主属性之间的依赖问题(如候选键之间的依赖)。
- 若表中存在依赖
4.Functional Dependency(函数依赖)
若表中属性X的值唯一决定属性Y的值
类型:
-
完全函数依赖:Y依赖于整个主键(如复合主键((StudentID, CourseID) \rightarrow Grade))。
-
部分函数依赖:Y仅依赖于主键的一部分(如(StudentID \rightarrow StudentName),在复合主键中违反 2NF)。
-
传递依赖:Y依赖于非主属性(如(ID \rightarrow Bank Code No \rightarrow Bank),违反 3NF)。
函数依赖判断范式的核心依据,通过分析函数依赖消除冗余和异常,指导表的分解。
4.30
1.Storage Management(存储管理)
(1)数据库存储基本结构
- 存储形式:数据库以文件形式存放在磁盘上,文件由多个 “页面(Page)” 组成(页面是磁盘与内存交互的最小单位,类似 “数据块”)。
- 页面作用:每个页面存储多个 元组(Tuple,即表中的一行数据),页面大小固定(如 256 字节、4KB 等)。
- 存储介质分类
- 易失性存储(Volatile):断电数据丢失,如 DRAM(内存)。
- 非易失性存储(Non-Volatile):持久化存储,如硬盘(HDD)、固态硬盘(SSD)。
SSD:固态硬盘(Solid State Drive)。HDD:混合硬盘(hybrid harddrive,HHD)
- 存储层次结构
访问速度(从快到慢):寄存器 → L1/L2缓存 → 主内存 → SSD → HDD → 磁带/光盘
容量(从小到大):寄存器(几字节)→ 缓存(KB/MB)→ 主存(GB)→ SSD/HDD(TB)→ 磁带(PB级)
特性:越上层越贵、速度越快、容量越小;越下层越便宜、速度越慢、容量越大。
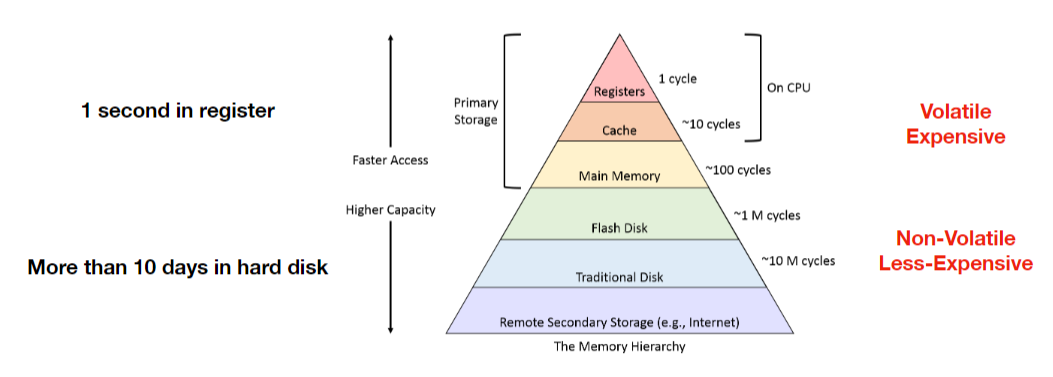
- HDD vs SSD 物理结构对比
- HDD:依赖磁头臂移动和盘片旋转,顺序访问快(因磁头无需频繁寻道),随机访问慢(寻道时间长),抗震性低(工作时抗 55g 冲击)。
- SSD:基于 NAND 闪存,无机械部件,顺序 / 随机访问均快于 HDD,抗震性强(抗 1500g 冲击),但写入寿命有限(约 10³-10⁵次擦写循环)。
(2)页面管理(Page Management)
- 页头元数据:每个页面包含 页 ID(唯一标识)、校验和(数据完整性检查)、版本号(并发控制)、元组状态数组(标记元组是否有效 / 删除)。
- 槽式页面(Slotted Page)核心机制
- 槽数组(Slot Array):存储每个元组的起始偏移量和状态(如是否被删除),页头记录 “已用槽数”,方便快速定位元组。
- 可变长度元组处理:元组数据区需额外存储长度信息,删除元组后通过槽数组标记空闲槽位,新元组可复用任意空闲槽(非仅页尾,区别于固定长度元组)。
- NULL 值与大值存储
- NULL 表示
全局位图:页头设一个位图,每一位对应一个元组的某个属性是否为 NULL(节省空间,适合多 NULL 场景)。
占位符值:为数据类型定义特殊值(如 INT 类型用 - 9999 表示 NULL,需业务层约定)。
属性级标记:每个属性前加 1 位标记位(1 = 有效,0=NULL),简单但增加存储开销。
- 大值处理
当元组超过页面大小时,DBMS 会:
- 使用溢出页(Overflow Page):主页面存指针,大值数据分块存在后续页面(如 PostgreSQL 的 TOAST 技术)。
- 存储到外部文件:元组仅存文件路径,适用于超大对象(如二进制文件、长文本)。
- 存储方式
- 页头(Page Header):记录页面基本信息(如已存元组数量、空闲空间等)。
- 槽位(Slot Entries):每个槽位记录一个元组在页面中的位置,类似 “索引标签”,方便快速定位元组。
- 元组存储:元组按顺序写入页面,固定长度元组直接连续存放,可变长度元组需额外记录长度信息。
- 操作逻辑
- 追加元组:直接在页面末尾写入新元组,页头更新元组数量(类似在笔记本新页末尾写新内容)。
- 删除元组:标记元组空间为 “可用”,后续新元组可复用该空间(类似划掉笔记本上的旧内容,留空位置写新内容)。
(3)页面存储效率
- 顺序访问 vs 随机访问
磁盘读取连续存储的页面(顺序访问)比分散存储的页面(随机访问)快得多(类比:在书架上按顺序找书 vs 随机翻找,前者更快)。
- 固定长度元组优势
固定长度元组(如每个元组占 20 字节)的存储和查询效率更高,无需额外处理长度信息(可变长度元组需多一步 “量尺寸”)。
- 对齐访问
- 数据在内存中需按数据类型长度对齐(如 8 字节数据存放在 8 的倍数地址),否则:ARM/RISC-V 等 CPU 会触发访问异常,X86 虽允许但会导致性能骤降(需多次非对齐读写)。
- 解决方案
填充(Padding):在属性间补空字节,强制对齐(如 16 位属性后补 2 字节,占 4 字节)。
字段重排序:按数据类型长度降序排列属性(长字段优先,减少填充开销)。
- 记录标识符(RID,Row Identifier)
DBMS 自动为每个元组生成唯一物理地址,用于快速定位:
- PostgreSQL:
CTID(6 字节,包含页号和槽位号)。- SQLite:
ROWID(8 字节,隐含表的物理存储位置)。- 应用场景:索引底层常依赖 RID 加速数据定位,但业务层不应依赖(物理位置可能变更)。
(4)典型计算示例(页面容量计算)
问题1:若页面大小 256 字节,页头占 16 字节,每个槽位占 4 字节,每个元组占 20 字节(固定长度),最多存多少元组?
问题2:
页面大小 512 字节,页头 20 字节,槽位 4 字节 / 个,记录大小依次为 [32, 28, 50, 40, 64, 45, 36](可变长度),按顺序插入,能存多少条?
计算公式还是
可以发现
通俗解释:数据库如何在磁盘上 “存东西”?
想象数据库是一个大账本,磁盘是账本的存储抽屉,每个 “页面” 就是账本中的一页纸:
- 每页纸的结构:
- 页头(纸的顶部):写着 “这页有 3 条记录”“还剩 50 字节空白”。
- 槽位(纸的边缘标签):每个标签标着 “第 1 条记录从第 10 字节开始,占 20 字节”,方便快速翻到对应位置。
- 记录(纸上的内容):每条记录像一行字,固定长度的记录(如 “姓名 20 字”)整齐排列,可变长度的记录(如 “备注”)需要额外标记长度。
- 往纸上写东西:
- 新增记录:直接在纸的末尾空白处写新内容,页头更新 “现在有 4 条记录”(类似在笔记本新行写东西)。
- 删除记录:划掉某条记录,标记这块空白可以写新内容,下次写记录时优先用空出来的位置(避免浪费纸张)。
- 找东西的效率:
- 如果记录按顺序写在纸上(如按学号排序),找起来很快(顺序访问);如果记录乱序分布(随机访问),就像在笔记本里乱翻,效率低。
通过这种 “分页管理”,数据库能高效地在磁盘上存储、查询和修改数据,就像用账本有条理地记录信息一样。
5.6
1.Clock
- 数据结构:环形队列 + 参考位(1 位),指针循环扫描,替代 LRU 的时间戳数组,空间效率更高。
- 优化点
- 避免 LRU 的 “Belady 异常”(容量增大时命中率可能下降)。
- 比 LRU 更易实现,适合内存受限场景(如嵌入式 DBMS)。
- 变种:Second Chance 算法(等价于 Clock):
若首次扫描到参考位 1,清 0 并跳过;再次扫描到 0 时才淘汰(给近期访问过的页面第二次机会)。
2.Localization(缓冲区本地化)
核心目标:防止单个查询(如全表扫描)占用过多缓冲池资源,导致高频访问页面被挤出。
实现方式
(以 PostgreSQL 为例):
- 查询级缓冲区配额:为每个查询分配固定数量的缓冲区帧(如最多使用 100 个页面),超出后强制释放。
- 局部性感知替换:将缓冲区分为 “全局区” 和 “局部区”,前者存储高频共享页面,后者临时存储查询专属页面(查询结束后释放)。
优势
- 隔离资源竞争:OLTP 查询(高频小数据量)和 OLAP 查询(低频大数据量)的缓冲区使用互不干扰。
- 减少 “缓冲区污染”:全表扫描加载的页面仅在查询生命周期内存在,不会长期占用缓冲区。
与 LRU-K 对比:
LRU-K 通过历史访问次数优化淘汰策略,Localization 则从查询粒度控制资源分配,二者可结合使用(如 PostgreSQL 同时支持本地化和 LRU 变种)。
3.缓冲区管理其他技术
-
Buffer Pool 组成
- 帧(Frame):缓冲区中的固定大小存储单元,与磁盘页面一一对应。
- 页表(Page Table):记录页面是否在内存中,包含元数据:
- 脏标志(Dirty Flag):页面被修改后标记为脏,淘汰前需写回磁盘(写回策略比写通更高效,减少 I/O 次数)。
- 固定标志(Pin Flag):防止重要页面被淘汰(如索引根节点),查询使用时 “固定” 页面,用完释放。
-
替换策略对比:
| 策略 | 核心逻辑 | 优势 | 缺点 |
| -------------- | --------------------------------------------- | ------------------ | -------------------- |
| LRU | 淘汰最久未访问的页面 | 简单有效 | 对顺序扫描不友好 |
| Clock | 基于 1 位参考位,扫描淘汰未访问页面 | 省内存,易实现 | 精度低于 LRU |
| LRU-K | 记录最近 K 次访问时间,淘汰最不可能访问的页面 | 平衡频率和近期访问 | 复杂度高,内存开销大 |
| MySQL 两段 LRU | 新页面先放 “旧列表”,再次访问移到 “新列表” | 避免短期热点 | |
- 预取优化(Prefetching)
DBMS 根据查询模式提前加载相邻页面(如顺序扫描时预取下一页面),减少 I/O 等待时间,尤其适合 HDD(机械寻道时间长)。
在数据库和多线程编程中,锁是一种非常重要的机制,用于解决多个进程或线程同时访问共享资源时可能出现的数据不一致问题。下面通俗地介绍一下锁和乐观锁,并举例分析:
- 锁的基本概念:可以把锁想象成一个房间的钥匙。当一个人(线程或进程)想要进入房间(访问共享资源)并对房间里的东西进行操作时,他需要先拿到钥匙。在他拿着钥匙的期间,其他人就不能进入房间,直到他把钥匙还回来。在编程里,锁就是用来控制对共享资源的访问顺序的工具,确保同一时间只有一个 “人” 能访问和修改共享资源,避免出现混乱。
- 悲观锁:悲观锁就像一个非常谨慎的人,他总是觉得别人会跟他抢东西。在数据库操作中,悲观锁认为在自己使用共享资源的过程中,一定会有其他线程来修改这个资源。所以,在访问资源前,它就会先把资源锁起来,其他线程只能等待锁被释放后才能访问。例如,在银行转账的场景中,A 向 B 转账 100 元。假设数据库里记录 A 账户余额的这一行数据就是共享资源,使用悲观锁时,当系统要读取 A 的余额时,就会马上给这行数据加上锁。在整个转账操作(读取 A 余额、扣除 100 元、写入新余额、读取 B 余额、增加 100 元、写入 B 新余额)过程中,其他任何操作都不能修改 A 和 B 的余额数据。只有等转账操作全部完成,锁被释放后,其他线程才能对这些数据进行操作。这样能保证数据的一致性,但缺点是如果有很多线程都要访问这些数据,就会有很多线程处于等待状态,性能会受到影响。
- 乐观锁:乐观锁则像一个乐观的人,他总是觉得在自己操作共享资源的时候,别人不会来抢。乐观锁假设在大多数情况下,多个线程不会同时修改共享资源。所以,它不会在一开始就锁定资源,而是在更新资源的时候,检查一下在自己读取资源之后,有没有其他线程修改过这个资源。如果没有,就正常更新;如果有,就采取一些措施,比如重新读取数据再尝试更新。还是以银行转账为例,系统读取 A 的余额时,不会加锁。在准备更新 A 的余额时,会检查 A 的余额在读取之后有没有被其他线程修改过。可以通过版本号或者时间戳来实现这种检查。假设给 A 的账户数据添加一个版本号,初始值是 1。系统读取 A 余额时,同时获取版本号 1。当要更新 A 余额时,再次检查版本号,如果还是 1,就说明没有其他线程修改过,允许更新,并把版本号更新为 2;如果版本号已经不是 1 了,就说明有其他线程修改过,那么就重新读取 A 的余额和最新版本号,然后再尝试更新。乐观锁的优点是并发性能好,因为大多数时候不需要等待锁的释放。但缺点是如果并发冲突比较频繁,就会导致很多次更新失败,需要不断重试,也会影响性能。
问题 1(LRU缓存算法)
你有一个容量为 3 的 LRU 缓存,在执行以下操作后,缓存的内容是什么?
操作步骤:
- Get(1)
- Put(1)
- Get(2)
- Get(3)
- Put(3)
- Get(2)
- Get(4)
- Get(1)
- Put(1)
- Get(5)
问题1使用的是 LRU 算法,LRU 关注的是数据的访问顺序,通过将最近访问的数据置于缓存靠前位置(最近使用),最久未访问的数据置于靠后位置(最久未使用),来决定淘汰策略。当有新数据插入时,若缓存未满,新数据直接插入到最近使用的位置(也就是最前面);若缓存已满,则淘汰最久未使用的数据(最末尾的数据) ,然后将新数据插入到最前面。
在 “put (1)” 和 “put (2)” 时,因为缓存未满,所以直接按访问顺序从前到后插入,先插入 1,再插入 2,就变成了 [2, 1],这里的顺序是基于最近使用的顺序,2 是最新使用的,所以在前面,1 在后面。
1.知识点讲解
LRU(Least Recently Used)缓存算法即最近最少使用算法。它的核心思想是,当缓存容量已满,需要淘汰数据时,优先淘汰最久未被使用的数据。就好比你有一个小书架,空间有限,新的书放不下了,你就会把很久都没看过的书拿走,给新书腾地方。在缓存中,每次访问一个数据,就相当于这本书被你拿出来看了,它就变成了最近使用的,会被放到更靠前的位置;而一直没被访问的数据,就会逐渐往后移,当缓存满了,最靠后的那个(最久未使用的)就会被淘汰。
2.答案解析
- Get(1):缓存中原本没有 1,所以未命中,从别处获取 1 放入缓存。此时缓存只有 1,所以缓存内容是 [1] ,也没有数据被淘汰。
- Put(1):1 已经在缓存中,对其进行更新,更新后它依然是最近使用的,所以缓存内容还是 [1] ,没有淘汰数据。
- Get(2):缓存中没有 2,未命中,获取 2 放入缓存。因为 2 是新访问的,所以放在最前面,此时缓存内容变为 [2, 1] ,无淘汰数据。
- Get(3):缓存中没有 3,未命中,获取 3 放入缓存。3 成为最近使用的,所以缓存内容变为 [3, 2, 1] ,没有数据被淘汰。
- Put(3):3 已经在缓存中,更新 3 后它还是最近使用的,缓存内容保持 [3, 2, 1] ,无淘汰。
- Get(2):缓存中有 2,命中。将 2 提升到最近使用的位置,也就是放到最前面,缓存内容变为 [2, 3, 1] ,没有数据被淘汰。
- Get(4):缓存中没有 4,未命中。但缓存容量已满,需要淘汰数据。根据 LRU 算法,最久未使用的是 1,所以淘汰 1,放入 4,缓存内容变为 [4, 2, 3] 。
- Get(1):缓存中没有 1,未命中。缓存容量还是满的,此时最久未使用的是 3,淘汰 3,放入 1,缓存内容变为 [1, 4, 2] 。
- Put(1):1 已经在缓存中,更新后缓存内容不变,还是 [1, 4, 2] ,无淘汰。
- Get(5):缓存中没有 5,未命中。缓存满了,淘汰最久未使用的 2,放入 5,缓存内容变为 [5, 1, 4] 。
| 步骤 | 操作 | 动作 | 缓存内容(最近使用 -> 最久未使用) | 是否淘汰 |
| ---- | ------ | --------------------------- | ---------------------------------- | ---------- |
| 1 | Get(1) | 未命中:获取 1 | [1] | 否 |
| 2 | Put(1) | 更新 1(已在最近使用位置) | [1] | 否 |
| 3 | Get(2) | 未命中:获取 2 | [2, 1] | 否 |
| 4 | Get(3) | 未命中:获取 3 | [3, 2, 1] | 否 |
| 5 | Put(3) | 更新 3(已在最近使用位置) | [3, 2, 1] | 否 |
| 6 | Get(2) | 命中:提升 2 到最近使用位置 | [2, 3, 1] | 否 |
| 7 | Get(4) | 未命中:获取 4(淘汰 1) | [4, 2, 3] | 是,淘汰 1 |
| 8 | Get(1) | 未命中:获取 1(淘汰 3) | [1, 4, 2] | 是,淘汰 3 |
| 9 | Put(1) | 更新 1(已在最近使用位置) | [1, 4, 2] | 否 |
| 10 | Get(5) | 未命中:获取 5(淘汰 2) | [5, 1, 4] | 是,淘汰 2 |
问题 2(时钟手LRU算法)
给定一个容量为 4 页的缓存,使用时钟手 LRU 算法进行管理。在执行以下操作后,缓存中存在哪些页面,它们的参考位是什么?
操作步骤:
- Get(1)
- Get(2)
- Get(3)
- Get(4)
- Get(2)
- Get(5)
问题2采用时钟手 LRU 算法,它以环形缓冲区的形式组织页面,主要依据页面的参考位(是否被访问过)来决定淘汰页面,对页面插入顺序没有像 LRU 那样严格按照最近使用顺序来排列。
“Get (2)” 时插入 2 并设参考位为 1,缓存变为 [1:1, 2:1],这只是简单地将新插入的页面添加到缓存中,没有涉及到按照特定顺序调整位置的操作 。这里只是单纯记录每个页面的参考位状态,在需要淘汰页面时,才会根据时钟手扫描参考位的结果进行操作,与第一题 LRU 算法中时刻维护严格的最近使用顺序不同。
1.知识点讲解
时钟手 LRU 算法是 LRU 算法的一种优化。每个页面都有一个参考位(1 位二进制数),当页面被访问时,参考位设为 1。页面组织在一个环形缓冲区中,有一个类似时钟指针的东西按顺序扫描这些页面。当需要淘汰页面时,指针开始扫描,遇到参考位为 1 的页面,就把参考位清 0 并跳过它;遇到参考位为 0 的页面,就淘汰该页面。这就像你在一个环形书架上整理书,每个书有个小标签(参考位),你拿着一个标记棒(时钟指针)依次检查。如果书的标签是 1(被看过),你就把标签擦掉(清 0)继续检查下一本;如果标签是 0(没被看过),就把这本书拿走(淘汰)。
2.答案解析
- Get(1):插入 1 并把 1 的参考位设为 1,此时缓存只有 1:1,没有淘汰数据。
- c
- Get(3):插入 3 并把 3 的参考位设为 1,缓存变为 [1:1, 2:1, 3:1] ,无淘汰。
- Get(4):插入 4 并把 4 的参考位设为 1,缓存变为 [1:1, 2:1, 3:1, 4:1] ,无淘汰。
- Get(2):命中 2,将 2 的参考位设为 1 ,缓存内容不变还是 [1:1, 2:1, 3:1, 4:1] ,无淘汰。
- Get(5):缓存已满,需要淘汰。时钟手从 1 开始扫描,1 的参考位是 1,清 0 后移动到 2;2 的参考位是 1,清 0 后移动到 3;3 的参考位是 1,清 0 后移动到 4;4 的参考位是 1,清 0 后又回到 1,此时 1 的参考位已经是 0 了,所以淘汰 1,插入 5 并把 5 的参考位设为 1,最终缓存内容是 [5:1, 2:0, 3:0, 4:0] 。
[!success]
在时钟手 LRU 算法的情境下,写成 [2:1, 1:1] 从存储内容的角度来说是可以的。因为该算法重点在于通过参考位和时钟手扫描来管理页面淘汰,对页面在缓存中的排列顺序并没有严格的 “最近使用 - 最久未使用” 顺序要求 。
在这个算法里,只要缓存未满,新插入页面时,你可以将其放在缓存中的任意位置(当然,一般习惯上会添加在末尾等位置,但这并非强制规定)。当缓存满了需要淘汰页面时,时钟手会按顺序扫描页面的参考位来决定淘汰对象,而不是依据页面在缓存中的排列顺序。所以 [2:1, 1:1] 和 [1:1, 2:1] 在表示缓存内容上是等效的,都记录了页面 1 和页面 2 已被访问(参考位为 1)且在缓存中的状态 。
不过,在实际应用和分析问题时,为了保持一致性和便于理解,通常会按照一定的顺序(如插入顺序或某种约定顺序)来书写缓存内容,但这并不影响算法的本质逻辑。
| 步骤 | 操作 | 动作 | 缓存内容(带参考位) | 是否淘汰 | 时钟手移动 |
| ---- | ------ | --------------------------- | ------------------------------------------------------------ | ---------- | ----------------------------------------- |
| 1 | Get(1) | 插入 1(参考位设为 1) | [1:1] | 否 | - |
| 2 | Get(2) | 插入 2(参考位设为 1) | [1:1, 2:1] | 否 | - |
| 3 | Get(3) | 插入 3(参考位设为 1) | [1:1, 2:1, 3:1] | 否 | - |
| 4 | Get(4) | 插入 4(参考位设为 1) | [1:1, 2:1, 3:1, 4:1] | 否 | - |
| 5 | Get(2) | 命中(将 2 的参考位设为 1) | [1:1, 2:1, 3:1, 4:1] | 否 | - |
| 6 | Get(5) | 未命中:需要淘汰 | 缓存已满,时钟手从 1 开始。1:R=1→清 0,移动;2:R=1→清 0,移动;3:R=1→清 0,移动;4:R=1→清 0,移动;1:R=0(之前已清 0)→淘汰页面 1,插入 5 并设参考位为 1。最终缓存内容:[5:1, 2:0, 3:0, 4:0] | 是,淘汰 1 | 依次检查 1、2、3、4 页后,淘汰 1 并插入 5 |
问题 3(分代缓存策略)
假设年轻代容量为 2,老年代容量为 2,在执行以下操作后,年轻代和老年代列表中的页面情况如何?
操作步骤:
- get(1)
- get(2)
- get(1)
- get(3)
- get(2)
- get(4)
- get(5)
问题3的分代缓存策略将缓存分为年轻代和老年代。新数据默认插入老年代,老年代中的数据若再次被访问则移动到年轻代。
在 “put (1)” 和 “put (2)” 时,数据都是新插入老年代,老年代的数据顺序按照插入顺序排列(从新到旧),所以是 [2, 1] ,2 是后插入的,相对较新,在前面,1 在后面。这种顺序和 LRU 算法中按照最近使用排序的逻辑不同,它是基于插入和访问的特定规则来管理数据在不同代缓存中的位置。
1.知识点讲解
这种缓存策略把缓存分为年轻代和老年代。新数据一开始会插入到老年代,如果老年代满了,就淘汰最老的数据。当老年代中的数据再次被访问时,会被移动到年轻代。年轻代也有容量限制,满了之后也会淘汰数据。这就像把书架分成了新书架(年轻代)和旧书架(老年代),新书先放旧书架,如果旧书架满了就扔掉最旧的书。旧书架上的书被重新翻看了,就把它放到新书架上,新书架满了也会扔掉最旧的书。
2.答案解析
- put(1):1 插入到老年代,年轻代没有数据,老年代是 [1] 。
- put(2):2 插入到老年代,老年代变为 [2, 1] ,年轻代还是空的。
- get(1):1 在老年代,被访问后移动到年轻代,年轻代变为 [1] ,老年代变为 [2] 。
- put(3):3 插入到老年代,年轻代是 [1] ,老年代变为 [3, 2] 。
- get(2):2 在老年代,被访问后移动到年轻代,由于年轻代容量为 2,放入 2 后满了,年轻代变为 [2, 1] ,老年代变为 [3] 。
- put(4):4 插入到老年代,老年代满了,淘汰最老的 2,老年代变为 [4, 3] ,年轻代还是 [2, 1] 。
- put(5):5 插入到老年代,老年代又满了,淘汰最老的 3,老年代变为 [5, 4] ,年轻代保持 [2, 1] 。
| 步骤 | 操作 | 年轻代列表(最近 -> 最久) | 老年代列表(最近 -> 最久) | 备注 |
| ---- | ------ | -------------------------- | -------------------------- | -------------------------------------- |
| 1 | put(1) | [] | [1] | 1 插入到老年代 |
| 2 | put(2) | [] | [2, 1] | 2 插入到老年代 |
| 3 | get(1) | [1] | [2] | 1 移动到年轻代 |
| 4 | put(3) | [1] | [3, 2] | 3 插入到老年代 |
| 5 | get(2) | [2, 1] | [3] | 2 移动到年轻代(年轻代已满) |
| 6 | put(4) | [2, 1] | [4, 3] | 4 插入到老年代(老年代淘汰最老的页面) |
| 7 | put(5) | [2, 1] | [5, 4] | 5 插入到老年代(老年代淘汰 3) |
4.B、B+树
(1)B树基础概念
B树是一种自平衡树数据结构,支持高效的搜索、插入、删除操作,时间复杂度均为 O(log n)。每个节点可包含多个键(分隔符)和子节点,适用于磁盘等外存设备,减少 I/O 次数。
核心特性
- 平衡特性:所有叶子节点位于同一深度,保证树高均衡。
- 节点填充:除根节点外,每个节点至少包含 ⌈m/2⌉-1 个键(m 为节点最大键数),至多 m-1 个键,确保节点 “半满”,减少分裂 / 合并频率。
- 键有序性:节点内键按升序排列,子节点键范围由父节点键划分(左子树键 < 分隔符键 ≤ 右子树键)。
(2)节点结构与树型特征
①节点组成
- 根节点:至少 1 个键,至多 m-1 个键(m 为节点最大容量)。
- 内部节点:含 k 个键,对应 k+1 个子节点,键作为子节点范围的分隔符。
- 叶子节点:无子女,存储键及对应值(B 树)或仅键(B + 树,值存于叶子)。
根节点:[20]
内部节点:[10, 35](左子树<10,中间10≤键<35,右子树≥35)
叶子节点:[6, 10, 20, 31, 38, 44](键有序排列)
②与二叉搜索树(BST)的区别
- BST 每个节点至多 2 个子节点,B 树可含多个子节点,树高更低(降低 I/O 次数)。
- BST 无节点填充限制,B 树通过 “半满” 规则减少树高波动,保证性能稳定。
(3)B + 树(数据库常用变种)
①与B树核心区别
- 值存储位置:B 树所有节点存储键和值;B + 树仅叶子节点存储值,内部节点仅存键(用于索引导航),空间利用率更高,查询更稳定(必达叶子节点)。
- 叶子节点连接:B + 树叶子节点通过双向指针串联(如
Prev/Next),支持高效范围查询(如SELECT * FROM table WHERE id BETWEEN 10 AND 20),无需回溯父节点。
②插入与删除算法
1.插入流程(以最大键数 3 为例,插入 6 到节点 [4,12])
(1)找到目标叶子节点,插入键并排序(如 [4,12]→[4,6,12],未溢出则完成)。
(2)若节点满(如插入 30 到 [15,25,35],变为 4 个键):
- 分裂为左右节点(左 [15,25],右 [30,35])。
- 中间键(30)上移至父节点,若无父节点则创建新根(形成分层结构)。
2.删除流程(如删除叶子节点 [5,10] 中的 5,导致下溢)
若删除后节点键数 <⌈m/2⌉-1,尝试向 “富裕” 的兄弟节点借键(如从右兄弟 [25,30,35] 借 25,合并到左节点 [10,25])。
借键失败则合并节点(如左兄弟 [10] 与右兄弟 [25,30,35] 合并,父节点删除分隔符 20,可能触发递归调整)。
例题 1:插入操作(最大节点容量m=3)
初始树结构:单个叶子节点 [15, 25, 35]
操作:插入 30
知识点讲解:B + 树的插入与删除规则
B + 树是数据库中常用的索引结构,具有以下核心特性:
- 节点容量:每个节点最多存储 m 个键(m 为节点最大容量),最少存储
- 插入规则:
- 找到目标叶子节点,插入键值对。
- 若节点已满(键数超过m),则分裂为左右两个节点,中间键上移到父节点,递归处理父节点。
- 删除规则:
- 找到目标叶子节点,删除键值对。
- 若节点键数不足(少于
答案解析
- 插入前检查:
- 叶子节点当前键:
[15, 25, 35],容量 (m=3),已满。 - 插入 30 后,键变为
[15, 25, 30, 35],超过容量,触发分裂。
- 叶子节点当前键:
- 分裂节点:
- 按中间位置(第2个键,索引从 1 开始)将键分为左右两部分:
- 左节点:前 2 个键
[15, 25](保留较小的一半) - 右节点:后 2 个键
[30, 35](保留较大的一半)
- 左节点:前 2 个键
- 中间键 30 上移到父节点。由于原节点是根节点,分裂后创建新的根节点
[30],左右子节点分别为左、右分裂节点。
- 按中间位置(第2个键,索引从 1 开始)将键分为左右两部分:

例题 2:删除操作(最大节点容量 m=3)
初始树结构:
- 根节点:
[20] - 左子节点(叶子):
[5, 10] - 右子节点(叶子):
[25, 30, 35]操作:依次删除 5 和 10
答案解析
- 删除 5:
- 左子节点
[5, 10]删除 5 后,剩余键[10]。 - 节点容量 (m=3),最小允许键数为
- 左子节点
- 删除 10:
- 左子节点
[10]删除 10 后,变为空节点,触发节点不足。 - 尝试向兄弟节点(右子节点
[25, 30, 35])借键,或与兄弟节点合并。 - 由于左子节点已空,选择合并:将父节点的键
20下移到左子节点,与右子节点合并为[20, 25, 30, 35],超过容量,需再次分裂? - 从父节点下移键
20,与右子节点的键合并后重新分配,最终左子节点为[20, 25],右子节点为[30, 35],父节点更新为[25]
- 左子节点
5.7
1.哈希表(Hash Table)
(1)定义与特性
- 本质:通过哈希函数将键映射到数组索引,实现快速键值对查找的数据结构。
- 核心操作:插入、删除、查询的平均时间复杂度为O(1),空间复杂度为O(n)。
- 内部结构:基于无序数组,通过哈希函数
(2)与B+树对比
| 特性 | 哈希表 | B + 树 |
| -------------- | ------------------------------------ | ------------------------------ |
| 有序性 | 无序(仅支持精确匹配) | 有序(支持范围查询、排序) |
| 查询复杂度 | 平均 O(1) | O(
| 适用场景 | 高频精确查询(如 Redis、PostgreSQL) | 范围查询、排序(如数据库索引) |
(3)核心问题与解决方案
核心挑战
- 问题 1:键空间大,无法预先分配足够内存。
- 问题 2:哈希冲突(不同键映射到相同索引)。
解决方案
- 哈希函数:设计快速、低冲突的函数(如 xxhash),将任意长度的键映射为固定长度整数。
- 冲突处理策略:线性探测(Linear Probing)、链地址法(Separate Chaining)、布谷鸟哈希(Cuckoo Hashing)等。
(4)冲突处理策略
线性探测(Linear Probing)
- 原理:冲突时顺序查找下一个空闲槽位插入,删除时标记 “墓碑”(Tombstone)以避免查找中断。
链地址法(Separate Chaining)
- 原理:每个槽位维护一个链表,冲突时将键值对添加到链表末尾。
布谷鸟哈希(Cuckoo Hashing)
- 原理:使用多个哈希函数(如
(5)核心公式与算法
哈希函数:
线性探测插入:若槽
布谷鸟哈希插入:对键
(6)例题
问题 1:线性探测冲突处理策略例题
知识点讲解
线性探测是哈希表冲突处理的一种策略,当插入键值对时若发生哈希冲突(即目标槽位已被占用),则按顺序探测下一个空闲槽位(如槽位 + 1,+2,…,循环到开头)。删除时需标记 “墓碑”(Tombstone),避免查找时因空洞中断。
核心规则
- 插入:计算哈希值,若槽位空闲则插入;否则顺序探测下一个槽位,直到找到空闲位置。
- 删除:标记槽位为 “已删除”(墓碑),插入时可重用该槽位,但查找时需跳过墓碑继续探测。
例题
哈希函数:(h(x) = x \mod 7) 表大小:7 个槽位(索引 0-6) 操作序列:
- 插入:10, 20, 15, 7, 32, 24
- 删除:15, 7
答案解析
- 插入 10:
- (h(10) = 10 \mod 7 = 3),槽 3 空闲,插入。
- 表状态:
[N, N, N, 10, N, N, N]
- 插入 20:
- (h(20) = 20 \mod 7 = 6),槽 6 空闲,插入。
- 表状态:
[N, N, N, 10, N, N, 20]
- 插入 15:
- (h(15) = 15 \mod 7 = 1),槽 1 空闲,插入。
- 表状态:
[N, 15, N, 10, N, N, 20]
- 插入 7:
- (h(7) = 7 \mod 7 = 0),槽 0 空闲,插入。
- 表状态:
[7, 15, N, 10, N, N, 20]
- 插入 32:
- (h(32) = 32 \mod 7 = 4),槽 4 空闲,插入。
- 表状态:
[7, 15, N, 10, 32, N, 20]
- 插入 24:
- (h(24) = 24 \mod 7 = 3),槽 3 被 10 占用,探测槽 4(被 32 占用),槽 5 空闲,插入槽 5。
- 表状态:
[7, 15, N, 10, 32, 24, 20]
- 删除 15:
- 槽 1 标记为 “Deleted”(墓碑),表状态:
[7, Deleted, N, 10, 32, 24, 20]
- 槽 1 标记为 “Deleted”(墓碑),表状态:
- 删除 7:
- 槽 0 标记为 “Deleted”(墓碑),表状态:
[Deleted, Deleted, N, 10, 32, 24, 20]
- 槽 0 标记为 “Deleted”(墓碑),表状态:
| 步骤 | 操作 | 哈希值计算 | 槽位状态(0-6) | 冲突处理 / 备注 |
| ---- | ------- | ----------------- | --------------------------------------- | -------------------------- |
| 1 | 插入 10 | (10 \mod 7 = 3) | [N, N, N, 10, N, N, N] | 无冲突,直接插入 |
| 2 | 插入 20 | (20 \mod 7 = 6) | [N, N, N, 10, N, N, 20] | 无冲突,直接插入 |
| 3 | 插入 15 | (15 \mod 7 = 1) | [N, 15, N, 10, N, N, 20] | 无冲突,直接插入 |
| 4 | 插入 7 | (7 \mod 7 = 0) | [7, 15, N, 10, N, N, 20] | 无冲突,直接插入 |
| 5 | 插入 32 | (32 \mod 7 = 4) | [7, 15, N, 10, 32, N, 20] | 无冲突,直接插入 |
| 6 | 插入 24 | (24 \mod 7 = 3) | [7, 15, N, 10, 32, 24, 20] | 槽 3 冲突,探测到槽 5 插入 |
| 7 | 删除 15 | - | [7, Deleted, N, 10, 32, 24, 20] | 标记墓碑,不影响探测 |
| 8 | 删除 7 | - | [Deleted, Deleted, N, 10, 32, 24, 20] | 标记墓碑,槽位可被重用 |
问题 2:链地址法(分离链接)冲突处理策略例题
知识点讲解
链地址法为每个哈希槽维护一个链表,冲突时将键值对添加到链表末尾。查询时遍历链表,删除时从链表中移除节点。
- 核心规则
- 插入:计算哈希值,将键值对添加到对应槽位的链表末尾。
- 查询 / 删除:计算哈希值,遍历链表查找目标键,删除时断开节点链接。
例题
哈希函数:(h(x) = x \mod 7) 表大小:7 个桶(0-6) 操作序列:
- 插入:15, 11, 27, 8, 3
- 查询:8(命中)
- 删除:11
答案解析
- 插入 15:
- (h(15) = 15 \mod 7 = 1),桶 1 链表为空,插入链表:
[15]。 - 表状态:桶 1:
15,其余桶为空。
- (h(15) = 15 \mod 7 = 1),桶 1 链表为空,插入链表:
- 插入 11:
- (h(11) = 11 \mod 7 = 4),桶 4 链表为空,插入链表:
[11]。 - 表状态:桶 1:
15,桶 4:11,其余桶为空。
- (h(11) = 11 \mod 7 = 4),桶 4 链表为空,插入链表:
- 插入 27:
- (h(27) = 27 \mod 7 = 6),桶 6 链表为空,插入链表:
[27]。 - 表状态:桶 1:
15,桶 4:11,桶 6:27,其余桶为空。
- (h(27) = 27 \mod 7 = 6),桶 6 链表为空,插入链表:
- 插入 8:
- (h(8) = 8 \mod 7 = 1),桶 1 已有 15,冲突,添加到链表末尾:
[15 → 8]。 - 表状态:桶 1:
15 → 8,桶 4:11,桶 6:27,其余桶为空。
- (h(8) = 8 \mod 7 = 1),桶 1 已有 15,冲突,添加到链表末尾:
- 插入 3:
- (h(3) = 3 \mod 7 = 3),桶 3 链表为空,插入链表:
[3]。 - 表状态:桶 1:
15 → 8,桶 3:3,桶 4:11,桶 6:27,其余桶为空。
- (h(3) = 3 \mod 7 = 3),桶 3 链表为空,插入链表:
- 查询 8:
- (h(8) = 1),遍历桶 1 链表,找到 8,命中。
- 删除 11:
- (h(11) = 4),遍历桶 4 链表,移除 11,链表为空。
- 表状态:桶 1:
15 → 8,桶 3:3,桶 6:27,其余桶为空。
步骤表格
| 步骤 | 操作 | 哈希值计算 | 桶状态(链表) | 冲突处理 / 备注 |
| ---- | ------- | ----------------- | ---------------------------- | -------------------------- |
| 1 | 插入 15 | (15 \mod 7 = 1) | 桶 1: [15] | 无冲突,新建链表 |
| 2 | 插入 11 | (11 \mod 7 = 4) | 桶 4: [11] | 无冲突,新建链表 |
| 3 | 插入 27 | (27 \mod 7 = 6) | 桶 6: [27] | 无冲突,新建链表 |
| 4 | 插入 8 | (8 \mod 7 = 1) | 桶 1: [15 → 8] | 冲突,添加到链表末尾 |
| 5 | 插入 3 | (3 \mod 7 = 3) | 桶 3: [3] | 无冲突,新建链表 |
| 6 | 查询 8 | - | 桶 1 链表命中 8 | 遍历链表找到目标键 |
| 7 | 删除 11 | - | 桶 4 链表移除 11,变为空链表 | 断开节点链接,不影响其他键 |
问题 3:布谷鸟哈希冲突处理策略例题
知识点讲解
布谷鸟哈希使用多个哈希函数(如 2 个)生成候选槽位,插入时优先选择空闲槽位,若冲突则驱逐现有元素并重新哈希。
- 核心规则
- 每个键有 2 个候选槽位:(h_1(key)) 和 (h_2(key))。
- 插入时,若两个槽位均被占,驱逐其中一个元素,递归重新哈希被驱逐的元素。
例题
哈希函数:
- (h_1(x) = x \mod 7)
- (h_2(x) = (x \div 7) \mod 7)(整数除法取商再模 7) 表大小:7 个槽位(0-6) 操作序列:插入 5, 12, 26, 19, 13, 48
答案解析(本质就是占了坑的就全部驱逐重新选坑)
- 插入 5:
- (h_1(5)=5),(h_2(5)=0)(5÷7=0),槽 5 空闲,插入槽 5。
- 表状态:
[N, N, N, N, N, 5, N]
- 插入 12:
- (h_1(12)=5)(冲突),(h_2(12)=1)(12÷7=1),槽 1 空闲,插入槽 1。
- 表状态:
[N, 12, N, N, N, 5, N]
- 插入 26:
- (h_1(26)=26 \mod 7=5)(冲突),(h_2(26)=3)(26÷7=3),槽 3 空闲,插入槽 3。
- 表状态:
[N, 12, N, 26, N, 5, N]
- 插入 19:
- (h_1(19)=19 \mod 7=5)(冲突),(h_2(19)=2)(19÷7=2),槽 2 空闲,插入槽 2。
- 表状态:
[N, 12, 19, 26, N, 5, N]
- 插入 13:
- (h_1(13)=13 \mod 7=6),(h_2(13)=1)(13÷7=1),槽 6 空闲,插入槽 6。
- 表状态:
[N, 12, 19, 26, N, 5, 13]
- 插入 48:
- (h_1(48)=48 \mod 7=6)(冲突,槽 6 有 13),(h_2(48)=6)(48÷7=6),两个候选槽位均为 6,冲突。
- 驱逐 13,重新哈希 13:(h_1(13)=6)(冲突),(h_2(13)=1)(槽 1 有 12),驱逐 12,重新哈希 12:(h_1(12)=5)(槽 5 有 5),(h_2(12)=1)(冲突),继续驱逐 5,重新哈希 5:(h_1(5)=5)(冲突),(h_2(5)=0),槽 0 空闲,插入 5 到槽 0。
- 最终表状态:
[5, 13, 19, 26, N, 12, 48]
步骤表格
| 步骤 | 操作 | 候选槽位 | 表状态(0-6) | 冲突处理 / 备注 |
| ---- | ------- | ---------------- | ---------------------------- | ------------------------------------------------------------ |
| 1 | 插入 5 | (h_1=5, h_2=0) | [N, N, N, N, N, 5, N] | 槽 5 空闲,直接插入 |
| 2 | 插入 12 | (h_1=5, h_2=1) | [N, 12, N, N, N, 5, N] | 槽 5 冲突,插入 h₂=1(空闲) |
| 3 | 插入 26 | (h_1=5, h_2=3) | [N, 12, N, 26, N, 5, N] | 槽 5 冲突,插入 h₂=3(空闲) |
| 4 | 插入 19 | (h_1=5, h_2=2) | [N, 12, 19, 26, N, 5, N] | 槽 5 冲突,插入 h₂=2(空闲) |
| 5 | 插入 13 | (h_1=6, h_2=1) | [N, 12, 19, 26, N, 5, 13] | 槽 6 空闲,直接插入 h₁=6 |
| 6 | 插入 48 | (h_1=6, h_2=6) | [5, 13, 19, 26, N, 12, 48] | 槽 6 冲突,驱逐 13→h₂=1(冲突 12),驱逐 12→h₁=5(冲突 5),驱 |
总结对比
| 策略 | 核心机制 | 优点 | 缺点 | 典型场景 |
| ---------- | ---------------------- | -------------------- | ---------------------- | -------------------- |
| 线性探测 | 顺序查找下一个空闲槽位 | 实现简单,空间紧凑 | 聚集现象,墓碑管理 | 小规模、低冲突场景 |
| 链地址法 | 每个槽位维护链表 | 冲突处理简单,无聚集 | 链表过长影响性能 | 高冲突、动态数据场景 |
| 布谷鸟哈希 | 多哈希函数 + 驱逐机制 | 高空间利用率,查询快 | 实现复杂,可能无限循环 | 内存敏感、高负载场景 |
5.13
| 存储过程名称 | 参数 | 功能描述 |
| ---------------------- | ------------------------------------------- | ------------------------------------------------------------ |
| BackupCriticalData | 无 | 备份关键数据表 (user, booking, customizeditinerary),并记录备份日志 |
| ConfirmBooking | p_booking_id | 确认预订,将状态从 "pending" 改为 "confirmed",支付状态改为 "paid" |
| CopyItinerary | p_itinerary_id, p_user_id | 为用户复制已有行程,包括基本信息和所有行程项目 |
| GenerateItinerary | p_user_id, p_city, p_start_date, p_end_date | 创建简单行程,根据城市和日期自动添加热门景点和酒店 |
| generate_itinerary | p_user_id, p_city, p_start_date, p_end_date | 创建个性化行程,根据用户偏好 (旅行风格、预算) 推荐景点和酒店 |
| recommend_scenic_spots | p_user_id, p_city | 根据用户兴趣和旅行风格推荐特定城市的景点 |
| RecordStrategyView | p_strategy_id | 记录攻略查看,增加攻略查看次数,提升相关城市景点热度 |
| RecoverData | p_recovery_point | 从备份恢复数据到指定时间点,恢复 user、booking 和 customizeditinerary 表 |
| SearchScenic | p_city, p_keyword | 搜索特定城市的景点,基于关键词匹配名称、描述或标签 |
| UpdateScenicHotScore | 无 | 更新所有景点的热度评分,基于评论、预订和收藏情况 |
| 触发器名称 | 作用时机 | 目标表格 | 功能描述 |
| --------------------------- | -------------- | ------------ | ------------------------ |
| after_booking_status_update | 修改预订状态后 | booking | 自动发送状态更新通知 |
| after_review_insert | 添加新评论后 | review | 根据评分自动调整景点热度 |
| after_strategylike_insert | 添加新点赞后 | strategylike | 自动增加攻略的点赞计数 |
| after_strategylike_delete | 删除点赞后 | strategylike | 自动减少攻略的点赞计数 |
1 | -- 触发器 |
1 | -- 存储过程 |
1 | -- 并发控制:乐观锁 |
1 | -- 1. 备份用户数据 |
1 | 查看当前用户数据 |
| 表名 | 锁类型 | 实现字段 | 实现方式 | 触发条件 |
| ---- | ------ | -------- | -------------- | -------------------------------------------------------- |
| room | 乐观锁 | version | 整数版本号自增 | 在预订房间后通过 after_booking_room 触发器自动增加版本号 |
| 视图名称 | 功能描述 | 基础表 | 主要字段 |
| ------------------------- | -------------------------------------- | -------------------------------------------- | ------------------------------------------------------ |
| view_bookingdetails | 预订详情信息,包括用户、景点和酒店信息 | booking, user, scenic, hotel | 预订信息、用户信息、景点信息、酒店信息 |
| view_cityscenicstats | 各城市景点统计数据 | scenic | 城市、景点数量、平均价格、最低价格、最高价格、平均热度 |
| view_hotstrategies | 热门攻略列表,按热度排序 | strategy, user | 攻略信息、作者信息、点赞和浏览量 |
| view_itineraryitemdetails | 行程项目详细信息 | itineraryitem, scenic, hotel, transport | 行程项目信息、景点信息、酒店信息、交通信息 |
| view_personalizedscenic | 个性化景点推荐 | user, userpreference, scenic | 用户信息、偏好城市内的景点信息 |
| view_useractivity | 用户活动统计 | user, strategy, booking, customizeditinerary | 用户信息、攻略数量、预订数量、行程数量、活跃度评分 |
| view_useritineraries | 用户行程统计信息 | customizeditinerary, itineraryitem | 行程信息、项目总数、景点数、酒店数、交通数、活动数 |
1 | <svg width="480" height="840" xmlns="http://www.w3.org/2000/svg"> |
1 | <svg width="480" height="840" xmlns="http://www.w3.org/2000/svg"> |
5.14
1.布隆过滤器(Bloom Filter)
(1)定义与特性
-
本质:一种概率型数据结构,用于高效判断元素是否存在于集合中,基于多个哈希函数和位数组实现。
-
核心特性
- 无假阴性:若查询返回 “不存在”,则元素必定不在集合中(False Negative Rate = 0)。
- 可能有假阳性:若查询返回 “存在”,元素可能不存在(由哈希冲突导致,False Positive Rate > 0)。
-
核心操作
- 插入:通过多个哈希函数计算元素的哈希值,将位数组对应位置置为 1。
- 查询:检查所有哈希函数对应位是否全为 1,全为 1 则 “可能存在”,否则 “必定不存在”。
-
空间效率:仅需维护一个位数组,空间复杂度远低于存储完整元素集合。
(2)核心问题与解决方案
核心挑战
- 问题 1:哈希冲突导致假阳性(False Positive)。
- 问题 2:位数组大小和哈希函数数量需平衡,以降低假阳性率。
解决方案
- 参数优化
设位数组大小为
- 多哈希函数:使用独立哈希函数减少冲突概率,如
(3)工作原理与示例
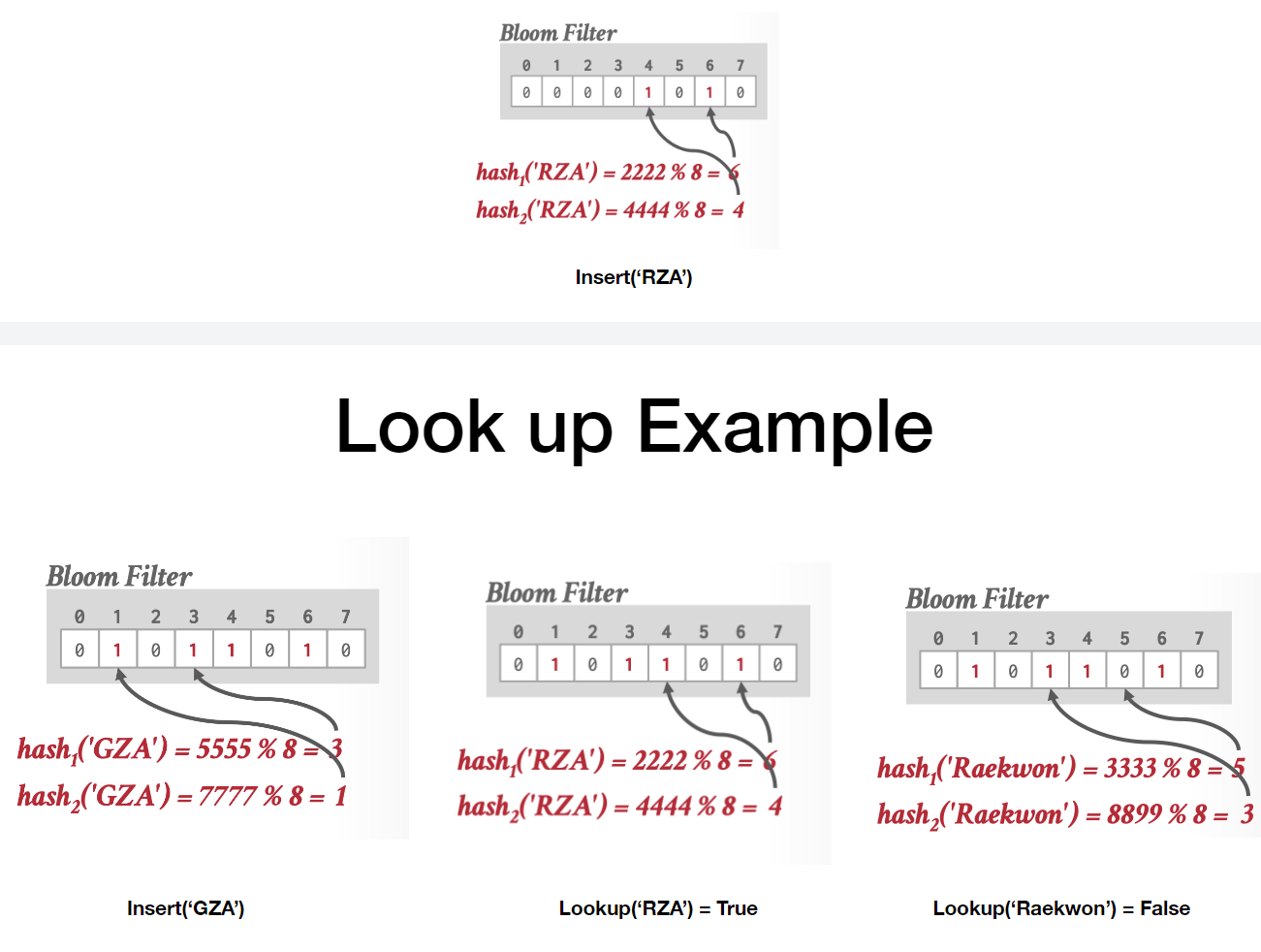
插入流程:对元素 x,计算k个哈希值
查询流程
- 对元素 x,计算 k 个哈希值,检查对应位是否全为 1。
- 若全为 1,返回 “可能存在”;否则返回 “不存在”。
示例(文档中的案例)(内容ai识别有误但可以辅助理解)
- 位数组大小:8(索引 0-7),哈希函数:2 个
- 插入 “RZA”:
- 插入 “GZA”:
- 查询 “ODB”:
- 查询 “假阳性案例”:某元素未插入,但所有哈希位被其他元素置 1(也就是置1的这两个位置分别是两个元素1的一部分,1个元素有两个1,组合在一起并没有实际的含义),返回 “存在”(如文档中 “ODB” 示例可能因哈希冲突误判)。
问题:布隆过滤器插入操作例题
知识点讲解
布隆过滤器是一种基于哈希函数和位数组的数据结构,用于高效判断元素是否存在于集合中。其核心思想是通过多个哈希函数将元素映射到位数组的不同位置,并将这些位置置为 1。插入时,所有哈希函数对应的位都会被标记;查询时,只有当所有哈希位均为 1 时,才认为元素 “可能存在”,否则 “必定不存在”。
核心规则
- 插入操作
- 对元素 x,计算每个哈希函数
- 对元素 x,计算每个哈希函数
- 无假阴性:若查询时任何一个哈希位为 0,元素必定不存在;若所有哈希位为 1,元素可能存在(可能因哈希冲突导致假阳性)。
例题
布隆过滤器设置:
- 位数组大小:10 位(索引 0–9)
- 哈希函数数量:2 个
- 哈希函数
-
- 操作序列:插入数字 5、7、12
答案解析
- 插入数字 5:
-
-
- 置位:索引 5(两个哈希函数均映射到 5,只需置位一次)。
- 位数组状态:
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
-
- 插入数字 7:
- (h_1(7) = 7 % 10 = 7)
- (h_2(7) = (7 \times 3) % 10 = 21 % 10 = 1)
- 置位:索引 1 和 7。
- 位数组状态:
[0, 1, 0, 0, 0, 1, 0, 1, 0, 0]
- 插入数字 12:
- (h_1(12) = 12 % 10 = 2)
- (h_2(12) = (12 \times 3) % 10 = 36 % 10 = 6)
- 置位:索引 2 和 6。
- 最终位数组状态:
[0, 1, 1, 0, 0, 1, 1, 1, 0, 0](与答案一致)
步骤表格
| 步骤 | 操作 | 哈希值计算 | 置位索引 | 位数组状态(0-9) | 备注 |
| ---- | ------- | ---------------- | -------- | ----------------------- | -------------------- |
| 1 | 插入 5 | (h_1=5, h_2=5) | 5 | [0,0,0,0,0,1,0,0,0,0] | 两哈希函数均映射到 5 |
| 2 | 插入 7 | (h_1=7, h_2=1) | 1, 7 | [0,1,0,0,0,1,0,1,0,0] | 无冲突,直接置位 |
| 3 | 插入 12 | (h_1=2, h_2=6) | 2, 6 | [0,1,1,0,0,1,1,1,0,0] | 无冲突 |
2.跳跃列表(Skip List)
(1)定义与特性
- 本质:基于多层有序链表的索引结构,通过分层指针实现快速搜索,常用于内存数据库索引(如 Redis)。
- 核心结构
- 多层链表:每层为有序链表,高层节点稀疏(约为下层的 1/2),底层包含所有节点。
- 随机层数:插入时通过 “抛硬币” 随机决定节点层数(概率 1/2 逐层递增,避免手动平衡)。
- 时间复杂度:搜索、插入、删除均为 (O(\log n))(近似平衡树效率)。
(2)与 B + 树对比
| 特性 | 跳跃列表 | B + 树 |
| --------------- | ---------------------------------- | ---------------------------- |
| 存储结构 | 内存有序链表(多层索引) | 磁盘友好的树结构 |
| 插入 / 删除 | 无需全局重新平衡(仅局部指针调整) | 可能触发树的分裂 / 合并 |
| 局部性 | 差(节点分散,缓存不友好) | 好(节点按页存储,局部性强) |
| 适用场景 | 内存型数据库、高频更新场景 | 磁盘数据库、范围查询为主 |
(3)核心操作流程
搜索流程
- 从最高层的头节点开始,沿当前层向右移动,直到下一个节点键值大于目标键。
- 若无法右移,下降到下一层,重复步骤 1,直到底层。
- 底层找到目标键则成功,否则不存在。
插入流程
- 找到插入位置(同搜索流程,记录各层前驱节点)。
- 插入底层节点,更新前驱节点的 next 指针。
- 抛硬币决定是否将节点提升到更高层(概率 1/2,直到达到最大层数),逐层更新指针。
(4)例题:插入节点与层数决策
场景:跳跃列表当前底层节点为 [11, 17, 20],层数最大为 3 层,插入节点 19。
- 底层搜索:17 < 19 < 20,插入位置在 17 和 20 之间。
- 抛硬币结果:第一次正面(层数提升至 2 层),第二次反面(停止提升)。
- 更新指针
- 底层:17→19→20。
- 2 层:若原 2 层节点为 [11, 20],插入 19 需判断是否在 2 层存在(因 19 未被提升到 2 层,故 2 层无变化)。
(5)优缺点
- 优点:实现简单,插入 / 删除高效(无需平衡),适合动态数据。
- 缺点:内存占用较高(每层节点需额外指针),磁盘访问效率低(非本地化存储)。
3.倒排索引(Inverted Index)
(1)定义与特性
- 本质:一种反向映射索引,将 “术语” 映射到 “包含该术语的文档集合”,用于高效文本搜索。
- 核心结构
- 词典(Dictionary):存储所有唯一术语,如 “car”“vehicle”。
- postings 列表(Postings List):每个术语对应一个文档列表,记录文档 ID 及出现位置 / 频率。
- 应用场景:全文检索(如 SQL 中的
LIKE '%关键词%')、搜索引擎、文档检索系统。
(2)核心问题与解决方案
核心挑战
- 问题 1:术语分词与标准化(如大小写、单复数处理)。
- 问题 2:高效处理多术语组合查询(如 “AND”“OR” 操作)。
解决方案
- 分词与归一化:使用分词器(如 Lucene 的 Standard Analyzer)将文本拆分为词元(Token),并转换为小写、去除停用词。
- 倒排列表合并
- AND 操作:取多个 postings 列表的交集(如归并排序遍历)。
- OR 操作:取多个 postings 列表的并集。
(3)示例:构建倒排索引
文档集合:
- “Winter is coming.”
- “Ours is the fury.”
- “The choice is yours.”
倒排索引表
| 术语 | 文档 ID 列表 | 频率 |
| ------ | ------------ | ---- |
| coming | [1] | 1 |
| fury | [2] | 1 |
| is | [1, 2, 3] | 3 |
| the | [2, 3] | 2 |
| yours | [3] | 1 |
查询 “is the”:
- 取 “is” 的文档列表 [1,2,3] 和 “the” 的文档列表 [2,3] 的交集,结果为 [2,3]。
(4)与正向索引对比
| 特性 | 倒排索引 | 正向索引(如 B + 树) |
| ------------ | ----------------------------- | -------------------------- |
| 映射方向 | 术语→文档(反向) | 文档→术语(正向) |
| 优势 | 快速回答 “哪些文档包含某术语” | 快速定位单个文档内容 |
| 适用场景 | 文本搜索、关键词查询 | 文档内容检索、精确主键查询 |
(5)扩展技术
- 同义词处理:引入同义词词典(如 “car” 映射 “vehicle”),扩展查询匹配范围。
- 短语查询:在 postings 列表中记录术语位置,支持 “邻近词” 搜索(如 “New York” 需连续出现)。
4.向量数据库(Vector Database)
5.14(2)sort
1.排序(Sorting)
(1)定义与特性
-
本质:将数据集合按升序或降序排列的过程,数据库中通过
ORDER BY实现,大规模数据需考虑内存限制采用外部排序。 -
核心操作
- 数据库排序:
ORDER BY排序结果集,LIMIT限制返回记录数,平均时间复杂度依赖数据规模和算法。 - 内部排序:在内存中直接排序(如选择排序、插入排序、快速排序),时间复杂度范围为 (O(n^2)) 到 (O(n \log n))。
- 外部排序:处理超出内存的数据,通过分块排序和归并实现(如外部归并排序)。
- 数据库排序:
-
内部结构
- 内部排序基于数组或链表操作,外部排序依赖磁盘分块和归并,利用优先队列优化 Top-N 排序。
(2)与其他排序方法对比
| 特性 | 内部排序(如快速排序) | Top-N 排序(优先队列) | 外部归并排序 |
| -------------- | -------------------------- | ----------------------------- | ------------------------------- |
| 数据规模 | 适合内存内数据 | 适合内存内数据 | 适合超大规模磁盘数据 |
| 时间复杂度 | (O(n \log n)) | (O(n \log k))(k 为 Top-N) | (O((n/m) \log (n/m) \cdot m)) |
| 内存依赖 | 需全部数据在内存中 | 仅需维护大小为 k 的堆 | 分块处理,每次仅加载部分数据 |
| 适用场景 | 中等规模数据排序 | 快速获取前 k 小 / 大元素 | 处理 TB 级无法内存容纳的数据 |
(3)核心问题与解决方案
核心挑战
- 问题 1:数据量超过内存容量,无法直接加载排序(如 128 TB 数据)。
- 问题 2:数据库中
ORDER BY结合LIMIT时,全量排序效率低。
解决方案
- 外部归并排序:分治策略,先排序内存可容纳的块,再逐次归并有序块(如 2 路归并)。
- Top-N 排序:使用优先队列(最大堆),仅维护当前 Top-N 元素,避免全量排序。
(4)核心算法步骤
Top-N 最小元素算法(最大堆)
- 初始化大小为 N 的最大堆。
- 遍历数据,若堆中元素数小于 N,直接插入堆。
- 否则,若当前元素小于堆顶(最大元素),删除堆顶并插入当前元素,调整堆结构。
外部归并排序(2 路)
- 排序阶段(Pass 0):将数据分块读入内存,排序后写回磁盘(生成 1-page 有序块)。
- 归并阶段(Pass 1, 2, ...):每次合并两个相邻有序块,生成双倍大小的有序块,直至所有数据有序。
(5)核心公式与算法
优先队列操作
- 插入元素:时间复杂度 (O(\log k))(k 为堆大小)。
- 删除堆顶:时间复杂度 (O(\log k))。
外部归并阶段数计算
设数据总页数为 n,内存可容纳 m 页,则归并阶段数为 (\lceil \log_{k}(n/m) \rceil)(k 为归并路数,此处 k=2)
问题 1:Top-N 最小元素算法例题(最大堆)
知识点讲解
使用最大堆维护当前 Top-N 元素,堆顶为当前最大元素。新元素若小于堆顶,则替换堆顶并调整堆,确保堆中始终为最小的 N 个元素。
核心规则
- 堆大小固定为 N,存储当前最小的 N 个元素。
- 新元素小于堆顶时,删除堆顶并插入新元素;否则跳过。
例题
目标:查找数组 [3, 8, 4, 9, 1, 5, 7, 11] 中前 3 小的元素。
步骤解析
- 初始化堆:堆大小为 3,初始为空。
- 插入前 3 个元素(3, 8, 4)
- 插入 3,堆:
[3](堆大小 1)。 - 插入 8,堆:
[3, 8](堆大小 2)。 - 插入 4,堆:调整为最大堆
[8, 3, 4](堆顶 8 为当前最大)。
- 插入 3,堆:
- 处理后续元素(9, 1, 5, 7, 11)
- 9 > 堆顶 8,跳过,堆不变。
- 1 < 堆顶 8,删除 8,插入 1,调整堆为
[4, 3, 1](堆顶 4)。 - 5 > 堆顶 4,跳过,堆不变。
- 7 > 堆顶 4,跳过,堆不变。
- 11 > 堆顶 4,跳过,堆不变。
- 最终堆元素:1, 3, 4(排序后为 [1, 3, 4])。
步骤表格
| 步骤 | 操作 | 堆状态(最大堆) | 对比结果 | 备注 |
| ---- | ------- | ---------------- | --------------- | ------------------------ |
| 1 | 插入 3 | [3] | - | 堆大小不足 3,直接插入 |
| 2 | 插入 8 | [8, 3] | - | 堆大小不足 3,直接插入 |
| 3 | 插入 4 | [8, 3, 4] | - | 堆大小达 3,调整为最大堆 |
| 4 | 处理 9 | [8, 3, 4] | 9 > 8,跳过 | 不更新堆 |
| 5 | 处理 1 | [4, 3, 1] | 1 < 8,替换堆顶 | 删除 8,插入 1,调整堆 |
| 6 | 处理 5 | [4, 3, 1] | 5 > 4,跳过 | 不更新堆 |
| 7 | 处理 7 | [4, 3, 1] | 7 > 4,跳过 | 不更新堆 |
| 8 | 处理 11 | [4, 3, 1] | 11 > 4,跳过 | 不更新堆 |
问题 2:2 路外部归并排序例题
知识点讲解
外部归并排序分排序阶段和归并阶段,每次归并两个有序块,逐步生成更大有序块,适用于数据量超过内存的场景。
核心规则
- 排序阶段:将数据分块读入内存,排序后写回磁盘(生成初始有序块)。
- 归并阶段:每次合并两个相邻有序块,生成双倍大小的有序块,直至所有数据有序。
例题
数据:磁盘上的数组 [17, 3, 9, 22, 13, 7, 5, 11],内存仅能容纳 4 个元素。
步骤解析
- 排序阶段(Pass 0)
- 分块 1:
[17, 3, 9, 22]→ 排序后[3, 9, 17, 22](写入磁盘)。 - 分块 2:
[13, 7, 5, 11]→ 排序后[5, 7, 11, 13](写入磁盘)。
- 分块 1:
- 归并阶段(Pass 1)
- 合并两个有序块:
- 比较 3(块 1)和 5(块 2),取 3,块 1 指针后移。
- 比较 9(块 1)和 5(块 2),取 5,块 2 指针后移。
- 比较 9(块 1)和 7(块 2),取 7,块 2 指针后移。
- 比较 9(块 1)和 11(块 2),取 9,块 1 指针后移。
- 比较 17(块 1)和 11(块 2),取 11,块 2 指针后移。
- 比较 17(块 1)和 13(块 2),取 13,块 2 指针后移。
- 取块 1 剩余元素 17、22。
- 生成最终有序数组:
[3, 5, 7, 9, 11, 13, 17, 22]。
- 合并两个有序块:
步骤表格
| 阶段 | 操作 | 内存中数据块 | 磁盘写入结果 | 备注 |
| ------ | -------- | ----------------- | --------------------- | -------------------------- |
| Pass 0 | 分块排序 | 块 1: [17,3,9,22] | 块 1: [3,9,17,22] | 生成初始有序块 |
| Pass 0 | 分块排序 | 块 2: [13,7,5,11] | 块 2: [5,7,11,13] | 生成初始有序块 |
| Pass 1 | 2 路归并 | 块 1 + 块 2 合并 | [3,5,7,9,11,13,17,22] | 合并两个有序块生成最终结果 |
总结对比
| 算法 | 核心机制 | 优点 | 缺点 | 典型场景 |
| ---------------- | --------------------- | ----------------------------------- | --------------------------- | ------------------------------ |
| Top-N 排序 | 最大堆维护 Top-N 元素 | 避免全量排序,节省时间 | 需维护堆结构 | 数据库 ORDER BY + LIMIT 场景 |
| 外部归并排序 | 分块排序后逐次归并 | 处理超大规模数据 | 多次磁盘 I/O 操作 | 处理 TB 级数据排序 |
| 快速排序 | 分治 + 分区交换 | 平均时间复杂度低((O(n \log n))) | 最坏情况 (O(n^2)),不稳定 | 内存中大规模数据排序 |
5.14(3)transaction and ACID(事务和ACID特性)
ACID是数据库事务的四个基本特性,分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
1.事务(Transaction)与 ACID 特性
(1)定义与特性
- 本质:数据库操作的基本单元,由一组逻辑相关的读写操作组成,确保数据一致性和可靠性。
- 核心特性(ACID)
- 原子性(Atomicity):事务中的操作要么全部执行,要么全部回滚(全或无)。
- 一致性(Consistency):事务执行前后,数据库约束(如主键、外键、CHECK 条件)保持成立。
- 隔离性(Isolation):事务执行时不受其他事务干扰,如同独占数据库。
- 持久性(Durability):已提交事务的修改永久保存,即使系统崩溃也不丢失。
- 生命周期:以
BEGIN开始,以COMMIT(提交)或ABORT(回滚)结束。
(2)ACID 核心特性对比
| 特性 | 核心作用 | 实现方式 |
| -------- | -------------------------------------------- | --------------------------------------------------- |
| 原子性 | 确保事务操作的完整性,失败时回滚到初始状态。 | 日志记录(Redo/Undo 日志)、影子分页。 |
| 一致性 | 维护数据库约束,确保业务规则不被破坏。 | 应用层约束定义、数据库内置约束(如 SQL 的 CHECK)。 |
| 隔离性 | 控制并发事务的交互,避免数据不一致。 | 并发控制协议(锁机制、时间戳排序、乐观并发控制)。 |
| 持久性 | 保证已提交数据的永久性。 | 日志持久化(WAL,预写日志)、磁盘同步。 |
(3)核心问题与解决方案
核心挑战
- 并发执行导致的数据不一致:如脏读(读取未提交数据)、丢失更新(覆盖未提交修改)、不可重复读(多次读取结果不同)。
- 事务失败后的状态恢复:部分执行的事务需回滚,已提交事务需持久化。
解决方案
- 并发控制协议
- 悲观协议:提前预防冲突(如锁机制,事务提前获取所需锁)。
- 乐观协议:假设冲突罕见,事后验证冲突并回滚(如版本控制)。
- 恢复机制:通过日志记录事务操作,崩溃后利用 Redo 日志重做已提交事务,Undo 日志回滚未完成事务。
(4)并发控制关键策略
冲突操作定义
两个事务对同一数据的操作满足以下条件之一:
- 读 - 写(RW)</strong>或<strong>写 - 读(WR):一个读,一个写。
- 写 - 写(WW):两个写操作。
可串行化调度
- 定义:多个事务的并发执行结果等同于某一串行执行结果(顺序不影响最终一致性)。
- 冲突可串行化:若两个冲突操作的顺序在调度中与某一串行调度一致,则该调度为冲突可串行化。
- 依赖图判断法
- 节点:事务(如 T1、T2)。
- 边:若事务 Ti 的操作先于 Tj 的冲突操作,添加边 Ti→Tj。
- 结论:若依赖图无环,则调度是冲突可串行化的。
(5)核心公式与算法
依赖图构建规则
- 每个事务为一个节点。
- 若 Ti 的操作 Oi 与 Tj 的操作 Oj 冲突,且 Oi 在 Oj 前执行,则添加边 Ti→Tj。
- 若图中存在环(如 T1→T2→T1),则调度不可串行化。
问题 1:判断冲突可串行化
操作序列:
T1: R(A) W(A)
T2: R(A) W(B)
T3: R(B) W(C)
知识点讲解
冲突操作仅发生在不同事务对同一数据的读写 / 写读 / 写写操作。本例中:
- T1 与 T2 对 A 有 RW 冲突(T1 读 A,T2 读 A 不冲突,因均为读;T1 写 A 与 T2 读 A 为 RW 冲突)。
- T2 写 B 与 T3 读 B 为 RW 冲突。
依赖图构建
T1→T2(T1 写 A 先于 T2 读 A?不,T2 读 A 在 T1 写 A 之前?需明确操作顺序。假设顺序为 T1.R (A), T2.R (A), T1.W (A), T2.W (B), T3.R (B), T3.W (C),则 T1 写 A 在
T2 读 A 之后,无冲突;T2 写 B 先于 T3 读 B,边 T2→T3。图无环,故冲突可串行化。
答案解析
需明确操作顺序:
若顺序为:
T1: R(A), W(A)
T2: R(A), W(B)
T3: R(B), W(C)
则:
- T1 与 T2 对 A 的操作:T1 写 A 在 T2 读 A 之后?若 T2 读 A 在 T1 写 A 之前,则无 RW 冲突(T2 读 A 时 A 未被 T1 修改)。
- T2 写 B 与 T3 读 B 为 RW 冲突,边 T2→T3。依赖图无环,调度冲突可串行化。
问题 2:脏读场景分析
事务序列:
T1: BEGIN, W (A, 10), 未提交
T2: BEGIN, R (A)(读取 T1 未提交的 A=10), ABORT
知识点讲解
脏读发生在事务读取另一个未提交事务修改的数据。若 T2 在 T1 提交前读取 A,且 T1 最终回滚,T2 读取的是无效数据。
答案解析
- T2 执行 R (A) 时,T1 未提交,属于脏读。
- 隔离性要求需避免此类场景(如通过读已提交隔离级别)。
总结对比
| 并发问题 | 现象 | 解决方案 |
| ------------ | ------------------------------ | ---------------------------------- |
| 脏读 | 读取未提交数据 | 提高隔离级别(如读已提交)、写锁。 |
| 丢失更新 | 后提交事务覆盖前事务未提交修改 | 行级锁、乐观锁(版本号校验)。 |
| 不可重复读 | 两次读取结果不同 | 快照隔离、范围锁。 |
| 幻读 | 新增数据导致范围查询结果变化 | 可串行化隔离级别、间隙锁。 |
通过 ACID 特性和并发控制协议,数据库确保了事务的正确性和可靠性,平衡了性能与一致性需求。
5.15(最后一次课)12.concurrency control并发控制
1.并发控制(Concurrency Control)
(1)定义与特性
- 本质:确保数据库事务并发执行时结果与串行执行一致(可串行化),通过锁机制或时间戳排序避免冲突。
- 核心目标:处理读写冲突(如脏读、不可重复读、幻读),保证数据一致性。
- 主要方法
- 锁机制:通过共享锁(S-Lock)和排他锁(X-Lock)控制对数据对象的访问。
- 时间戳排序(Timestamp Ordering):为每个事务分配唯一时间戳,按时间戳顺序处理操作,冲突时回滚事务。
(2)与时间戳排序对比
| 特性 | 锁机制 | 时间戳排序 |
| ------------ | -------------------- | -------------------- |
| 冲突处理 | 阻塞等待(可能死锁) | 回滚重启(无死锁) |
| 执行顺序 | 由锁获取顺序决定 | 由时间戳顺序决定 |
| 系统开销 | 锁管理开销、死锁检测 | 时间戳维护、回滚开销 |
| 适用场景 | 高竞争、长事务 | 低冲突、短事务 |
(3)核心问题与解决方案
核心挑战
- 问题 1:锁冲突导致死锁(多个事务循环等待锁)。
- 问题 2:级联回滚(Cascading Abort):一个事务回滚导致依赖它的事务也回滚。
- 问题 3:读写顺序冲突(如写 - 读、读 - 写冲突)。
解决方案
- 死锁处理:超时检测、等待图检测(Cycle Detection)或银行家算法(通过安全序列避免死锁)。
- 避免级联回滚:使用严格两阶段锁(Strict 2PL),事务提交前不释放写锁。
- 冲突控制
- 锁机制:通过兼容性矩阵(如 S 锁与 X 锁互斥)控制并发访问。
- 时间戳排序:通过比较事务时间戳与数据对象的读写时间戳(R-TS/W-TS)决定是否允许操作。
(4)关键策略与协议
1. 锁类型与兼容性矩阵
-
S-Lock(共享锁):允许多个事务同时读取同一数据项,但禁止其他事务写入。
-
X-Lock(排他锁):独占数据项,禁止其他事务读写。
-
锁兼容性矩阵:
| 现有锁 \ 请求锁 | S-Lock | X-Lock |
| ------------------------------------------------------------ | ------ | ------ |
| S-Lock | 允许 | 拒绝 |
| X-Lock | 拒绝 | 拒绝 |
| 例如,若事务 T1 持有 S 锁,事务 T2 可申请 S 锁(共享读),但 T2 申请 X 锁会被拒绝。 | | |
assignment 3前置练习:B+树
B+ Tree
Construct a B+ Tree where each node can hold a maximum of 4 keys.
To ensure consistency and avoid ambiguity during node splits, follow these rules:
-
Splitting Rule: When a node overflows (i.e., receives a 5th key), split it into two child nodes such that the right node contains more keys than the left node (in case of an odd number).
-
Promotion Rule:
Leaf Node Split: Copy (do not move) the leftmost key of the right node up to the parent. Leaf nodes store actual data, so the inserted key must remain in the leaf.
Internal Node Split: Move the leftmost key of the right node up to the parent. Internal nodes are used purely for navigation, so the promoted key is removed from the child node to reduce redundancy. (This splitting behavior differs from that presented in our lecture slides. However, both approaches are considered acceptable in practice. For the purposes of this exercise, please follow the rule described above)
- Deletion Rule:
When a key is deleted and a node underflows (i.e., it has fewer than the minimum number of keys), attempt to borrow a key from a sibling. If borrowing is not possible, merge the underflowed node with a sibling, and remove the separating key from the parent. This can cause cascading merges up the tree.
If, as a result of merging, the root node ends up with only one remaining child, the root is removed, and its single child becomes the new root, effectively reducing the height of the tree by one.
Task 1: Insert the following sequence of keys and draw the final tree
10, 20, 5, 6, 12, 30, 7, 17, 3, 25, 27, 4, 31
Task 2: Delete the following number of keys 3, 4, 25 Tip: You can use the visualisation tool to verify your answer
(https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html)